Teachable Machineで機械学習:Coral EdgeTPU+Raspberry piでハンドサインを認識させる
はじめに
前にlobeを用いた機械学習の記事を書きました。今回はgoogle creative labのTeachable Machineでモデルを作り、Raspberry piでハンドサインの認識をさせてみます。モデルを利用するためのexample codeがEdge TPUを利用するものだったので、ずいぶん前に購入してそのままになっていたCoral USB acceleratorを引っ張り出して使いました。Raspberry piは、lobeの記事の時にも用いたRaspberry pi 3A+です。USB3.0がないのでacceleratorの威力も限定的かもしれませんが、どうなるか試してみることにします。
やること構想
アメリカのハンドサインから、一文字アルファベットをいくつか選んで材料とします。カメラの前にハンドサインをかざして認識させ、うまくいけばエアコンやテレビのリモートコントロールと連携させたい。このあたりは何とどう連携させてもいいわけで、まずはハンドサイン認識の学習と、Raspberry pi上で識別プログラムをうまく動かすところから始めたい。

材料
- Raspberry pi 3A+とカメラなどは前の記事参照。まったく同じものを用いています。
- Coral USB accelerator
Tensorflow lite用のexample codeをRaspberry pi上で動かすために必要です。 - 1.3″ 128×64 OLED display (I2C接続可能)
判定ラベルと確率を表示させるために使います。 - ReSpeaker 2-Mics Pi HAT
もともと音声データを用いた学習をさせるためにTeachable Machineに目をつけ、このHATをのせました。音声入力、スピーカー用のアンプ、RGB LEDが3つと、てんこ盛りのお買い得HAT。今回は認識成功のフィードバックとしてLEDを光らせるために使います。 - トレーニングデータ撮影用USBウエブカメラ(logitech C615)
Laptopについているものでもいいのですが、背景選択や画角の調整には自由に動かせるUSBカメラが便利です。
セットアップは以下のようになりました。スピーカーがpi HATにつながっていますが、今回は使いません。

Raspberry pi ライブラリインストールなど
以下のものをインストールします。
- pycoral APIが今日の段階で最新なのですが、Teachable Machineからのexampleがまだ対応していません。deprecatedとなっているpython3-edgetpuを入れます。
- SSD1306 library
今回のOLEDを使うためのもの。使わない場合不要。 - ReSpeaker 2-Mics Pi HAT をRaspberry piと使うためのライブラリ。Seeed studioのgetting startedのページを参考にして導入します。
- Raspberry pi上でのユーザーをi2c, spiグループに追加しておきましょう。
# spi, i2cに自身のユーザーを追加しておく。
sudo adduser <user name> spi
sudo adduser <user name> i2c
# python version
python3 -V
python 3.7.3
sudo apt update
sudo apt install python3-edgetup
# edgeのつくパッケージを調べてみる。
sudo dpkg -l | grep edge
ii libedgetpu1-legacy-std:armhf 15.0 armhf Support library for Edge TPU
ii python3-edgetpu 15.0 armhf Edge TPU Python API
Teachable Macineを使う(うんちくありで長い)
lobeもいいんですが、これも本当に面白い!音の識別も試すことができるのは本当にスゴイ。実際に試してみると、サンプリングの難しさもよくわかる。例えば、「いってきます」と「ただいま」を識別したいとする。音のサンプルはある長さ(たとえば1秒)で区切って一つとするので、「いってきます」がうまくその区切りに入るように切り取らなければならない。また、認識時にも音の連続入力のなかから「いってきます」が入るような大きさのフレームを、重なりをもたせつつずらしながら見ていくという処理が必要となる。画像の場合とはかなり異なる工夫とマシンパワーが必要だとわかってくるのもオモシロイのです。
さて、音のことを書いておきながら、今回は画像でいきます。というのは、音の識別の場合、モデルを使うために提供されるサンプルコードがウェブブラウザーの使用を前提としたものであるため、Raspberry pi 3A plusでの実行には荷が重く、処理のもたつきが、ことばをうまく拾うタイミングを逃すようで、判定ミスが連続して楽しくありません。NVIDIAのjetson nano(2GB)を使うとうまく処理できることが分かったのですが、空冷ファンもうるさく回り始めますし、今回は中堅Raspberry piにこだわることにして画像サンプルで学習を行うことにします。(音の解析、ことばの認識は本当に奥が深い。まだまだ勉強が必要です)
まず、Teachable Machineのページを開き、Get Startedをクリック。New Projectのページがひらきます。
Image Projectをクリック。
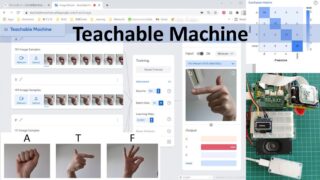
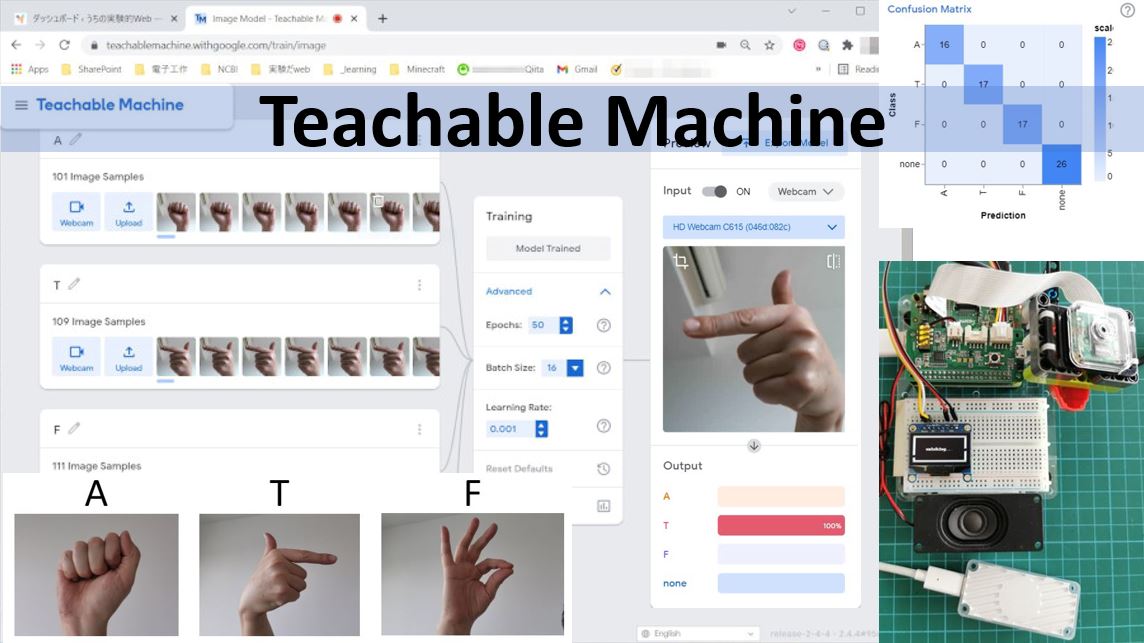
Standard image modelのほうをクリック。Class 1とClass 2が最初から用意されています。鉛筆マークをクリックしてクラス名をA、Tに変更。あと二つ、Fとnoneクラスを作りたいので、下にあるAdd a classをクリックしてクラスを追加します。
Aクラスの画像データを追加します。USBカメラを使いたいので、Webcamをクリックして選択します。背景がシンプルになるようにカメラの向きを決めます。今回はハンドサインを使うので、手をかざしやすい向きであることも重要です。まったく何もない背景である必要はないようですが、いろいろ試してみてください。
手をうまくカメラに向けて、Hold to Recordボタンを押します。押している間、だだだだだーっとフレームが保存されていきます。少しづつ手の向きやカメラとの距離を変えたりして、こんな風に見えるかもね、をできるだけ教えるつもりで撮影します。100枚ぐらいを目安にしました。
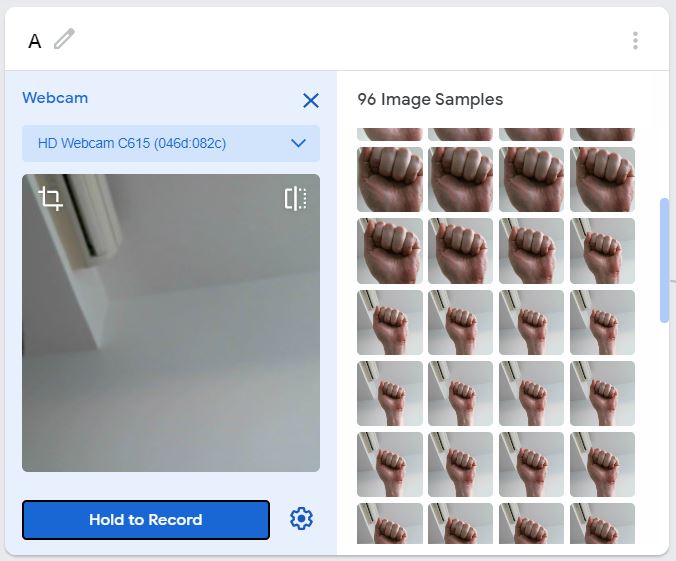
A、T、Fを撮影したあと、noneクラスには背景だけが写るようにして天井や壁などを撮影。ちょっと枚数が多めになりましたが、よしとしました。
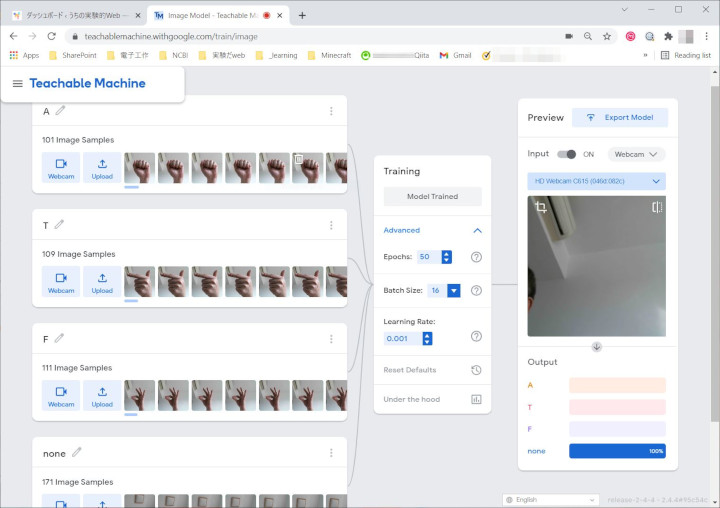
さあ、いよいよです。Trainingのところにある、Train Modelを押せばトレーニングが始まります。
せっかくですので、ちょっと寄り道してAdvancedをクリックして舞台裏をのぞいてみましょう。EpochsやBatch Size、Learning Rateの項目が見えます。トレーニングは、与えられたサンプルすべてを使って一度に行われるのではなく、Batch Sizeで指定した数ずつにサンプルを分割して行われます。分割したバッチをすべてカバーし終わると1 epochです。サンプルはシャッフルされて再度バッチに分割され、トレーニングが繰り返されます。50 epochとはこれを50回繰り返すということです。それぞれのサンプルについてみると、50回トレーニングに供されるということになります(50 passes)。
Learning Rateについてですが、トレーニングではパラメターを少しずつ変更して最適を目指します。このとき、一歩をどのぐらいの歩幅でとるかがLearning Rateです。歩幅が小さいと、最適にたどり着くのに時間がかかりすぎて結局たどりつけなかったり、小さな山の向こうにもっといい最適があるのに一歩が小さいばかりに手前で右往左往して峠越えができなかったりします。一方、歩幅が大きすぎると最適をまたいで山の向こう側へ行ってしまうことがあり、この場合も最適を逃すことになってしまいます。
今回はすべてデフォルトでトレーニングを行いました。興味のある方は、Advancedにあるパラメター設定を変えてどういう影響がでるのか試してみましょう。
トレーニングが完了すると、Train ModelがModel Trainedにかわります。
一番下にある、Under the hoodをクリックすると、トレーニングの結果を見ることができます。(Vocabをクリックするといくつかのtermに関する説明がでてきますので読んでおきましょう)
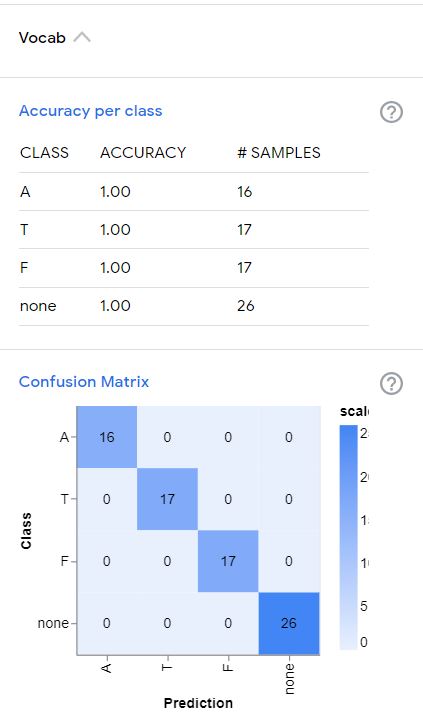
サンプルの15%はトレーニングに使わないでとっておき、トレーニング完了後に”前に一度も見たことないデータ”としてモデルの出来具合チェックに使われる、とあります。トレーニング用とテスト用とにどうサンプルをわけるかは重要なポイントです。特にサンプル数が限られているような場合には、一つを除いて残りでトレーニング、除いておいた一つをテスト、という風にして、除いておく一つを順に変えながらすべてについて行うというやりかたもあります(leave-one-out)。
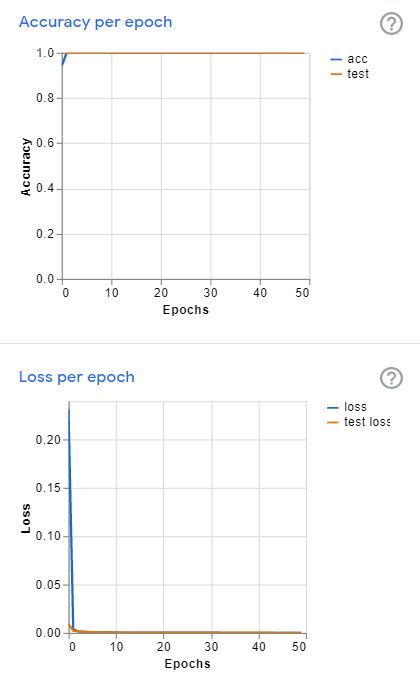
結果をみると、テストもバッチサイズ(前後)で行われるようですね。accuracyはすべて1ですね。下にあるconfusion matrixはどれのはずのものが、どれとして判定されたか、をまとめた表です。どれをどう間違いやすいのかを見つけるのに便利な表です。今回は対角線上以外がすべて0なので、間違った判定がなかった、ということです。accuracy=1とも辻褄があいますね。
さらにトレーニングの進み具合のグラフが二つあります。うわー、今回は最初の数epochで一気にカタが付いてしまっていますね。Accuracyは天井うち、lossも開始直後に地面を這っています。Accuracyもlossもトレーニングの仕上がり具合の指標なのですが、連続した値となるlossのほうを使ってチューニングは進みます。Accuracyは一つ正解が増えるか減るかで、値が不連続になってしまい、微分を指標にして進むチューニングには使えないのです。
うんちく長すぎ。
モデルを保存しましょう。Raspberry piで使いたいのでTensorflow Liteを選びます。え?Model conversion typeって何?わからないので全部とって試しましたところ、私の今回の環境ではQuantizedしか動きませんでした。他は何らかのエラーを出し、解決への努力姿勢はどこへいったんだ、と思いましたが、動くものがひとつあればそれでいいので、すみません、勘弁してください。
converted_tflite_quantized.zipがダウンロードされます。中にはmodel.tfliteとlabels.txtが入っています。この二つのpathをコードに書いて使います。
サンプルコードをコピーし、モデルファイルとlabelファイルのパスを書き込めば使えるはずなのですが、私の場合cv2.imshow(‘frame’, cv2_im)がうまく動かず、コメントアウトしました。Pillowやopencvのインストールがされていない場合は指示にあるとおりに導入してください。
Projectはgoogle driveに保存しておくことが可能です(便利)。
左上の三本線をクリックして、Save project to Driveを選択するだけです。
Web上での判定動作はこんな感じになります
動画をご覧ください。これはノートパソコン上での動作です。サクサク判定がされます。トレーニングに使わなかった手の形もここで試してみています。リアルタイムでフィードバックが見えるので、あれこれほかのものをカメラの視野にいれて遊んでみてください。
コード
コードはGitHubにのせておきましたが、セットアップも異なると思いますし、今回私の手(右手)でしかトレーニングを行いませんでしたので、そのままではうまく動かない可能性が高いと思います。参考例としてご覧ください。
EdgeTPU用のライブラリに注意が必要です。 Example codeとしてTeachableMachineから得られるコードでは執筆時点で、”from edgetpu.classification.engine import ClassificationEngine”が使われていて、python3-pycoralを導入すると動きません。python3-edgetpuのほうをインストールしてください。でもこれ、Edge TPU Python API のページではdeprecatedって書かれているんですよ。ちょうど移行期なんですかね。近いうちにexample codeのほうがアップデートされることを期待しましょう。
実際の動作の様子
動画をご覧ください。
こんなことしたら楽しかった
上の二つの動画にもあるのですが、トレーニングに使わなかった手の形を見せるとFの判定がでています。特徴としては上に向かって伸びる指なのではないかと思われます。というようなことを考えているときに、子供がカメラの視界に入って変顔をし始めました。お。顔をいろいろに変えて、Aが出せたら勝ち、とかやってみるかということで、しばらく試しましたが難しすぎました。でも、こういうのはオモシロイかもしれない。手に限らず、何かの形を認識させて、それと同じ判定がでるようなものを他から探してくる。もしそれができれば、まさにこの機械学習が捉えている特徴を見つけたことになります。みなさんもいろいろ遊んでみてください。
今後
今回試した限りではうまく動きそうな感じです。Aをエアコン、Tはテレビ、Fは扇風機のON-OFFに割り当てようかなという魂胆でアルファベットを選びました。あとはRM3 miniと連携すればハンドサインリモコンの出来上がりです。
今回ハンドサインの認識フィードバックをLEDからの色とOLEDへの表示にしたのは、音の認識がしにくい人たちや騒音のひどい状況での使用を考えた場合、音でのフィードバックでは意味がないと考えたからです。そもそもハンドサインは音を介さずにコミュニケートするための手段ですから音でのフィードバックでは一貫性がないのです。
この記事では示しませんでしたが、ハンドサインのAとSとはかなり似通っていて、判別できないのではないかと思いましたが実際に試してみるとかなりの高精度で分類されます。試していませんがMとNも似ています。ぜひご自分の手で(まさに!)お試しください。