Microsoft lobeで機械学習:得られたtfliteモデルを使ってRaspberry pi上でLegoブロックの分類をする

はじめに
Adafruitのページを見ていて、lobeという面白そうなソフトがあるのを見つけました。Tourを見てみると、パソコンのweb cameraから画像を取り込んでラベルを付け、即座に始まるtrainingの結果を見ながら間違ったものにラベルしなおしたり、画像を追加したりしながら学習を進め、すぐに判定を試してみることができるというものです。これはすごい。Web cameraのついたパソコンがさえあればすぐに試すことができます。
まずは、家族の顔の判定ができるかどうかをやってみました。
できる!完全ではないし、背景や光の加減で判定がぶれますが、そういうことがいろいろ試す中でだんだんわかってくるのも面白いところです。とにかく機械学習の一連の過程にここまで簡単に触れられるようにしたのはすごいと思います。
さて、すごいすごいで終わってはいられません。lobeは学習したモデルをほかのプログラムから使える形で出力することができるので、それを使ってみるところまでやってみることにしました。技術は使って触れてみるのが一番。
なにをしたいか
Legoのブロック何種類かを分類するプログラムを作りたい。トレーニング用には静止画、分類時には動画を入力として用いたい。
lobeには、web cameraからの画像のほか、外部で用意した画像とラベルをdatasetとして渡すこともできる。分類はRaspberry pi上で行いたいので、datasetもRaspberry piで準備したい。判定のための画像を取り込むカメラと、training用の画像を得るカメラは同じほうがいいはず。
やること構想
(1)Raspberry piで静止画を(簡単に)撮影できるようにする。
(2)分類したいものの写真をどんどんとって、データフォルダにため込む。
(3)得られたデータフォルダをパソコンに転送してlobeで学習を行う。
(4)TensorFlow Lite用にモデルをexportしてRaspberry piに転送する。
(5)得られたtfliteモデルを使って判定をさせる。
材料
- Raspberry pi 3A plus
判定プログラム(動画からの入力)では動きがのんびりしますが、仕事はしてくれます。Raspberry pi 4(欲しいなあ)を使えばもっと速くなるのかどうかはわかりません。


- Adafruit Raspberry Pi Camera Board Case with 1/4″ Tripod Mount
三脚などへの取り付けができるねじ穴がついていて便利です。 - Web camera stand
上からの画像をとるためには長めのものが便利です。 - 分類に使うLego blockたち
今回は1×1、1×2、1×4、2×2、2×3、2×4のそれぞれ5色と(ここには白のみ写っています)、Lego Technicシリーズのビーム数種類(LegoTech)、あとはどちらでもないもの(NonLego)3つを使いました。

全体のセットアップはこんな感じです。

Raspberry piの準備
OSのバージョンは以下の通り。
pison@3Ap1:~ $ cat /etc/os-release
PRETTY_NAME="Raspbian GNU/Linux 10 (buster)"
NAME="Raspbian GNU/Linux"
VERSION_ID="10"
VERSION="10 (buster)"
VERSION_CODENAME=buster
ID=raspbian
ID_LIKE=debian
HOME_URL="http://www.raspbian.org/"
SUPPORT_URL="http://www.raspbian.org/RaspbianForums"
BUG_REPORT_URL="http://www.raspbian.org/RaspbianBugs"
Training用の画像を撮影させるためのプログラム、buildDatasets.pyを動かすために必要なライブラリ、OpenCVとimutilsをインストールします。OpenCVのインストールに関してはreference (2)とそこからのリンクを参考にしました。(情報が多くて最初は混乱しました)
# OpenCV
sudo pip3 install opencv-contrib-python
# imutils
sudo pip3 install imutils
TensorFlow Lite用のモデルを使うためのruntimeは、reference (3)に従ってインストールします。idLegoBlock.pyを動かすために必要です。
echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
sudo apt-get update
sudo apt-get install python3-tflite-runtime
pillowやnumpyが入っていない場合にはそれらもインストールしておきます。何かが足りない場合にはコードを走らせる際にその由伝えるエラーがでて教えてくれるはずなので、あきらめずに解決してください。
training用のdatasetを用意する
reference (1)を参考にbuildDatasets.pyを書きました。キーボードのkを押すたびに一枚写真をとり、指定された出力先(保存先)のフォルダに連番を振りながらjpgファイルを保存してくれます。qを押すと終了します。
作業ディレクトリの準備
あとでlobeに学習させる際、フォルダ名をラベルとして使うことができるので、下にあるような構成で空のフォルダを用意しておきました。dataset1の下にLego1x1、Lego1x2など。本質的でないエラーを避けるため、フォルダ名にはスペースを入れない、日本語(全角文字)も避ける、が基本です。
pison@3Ap1:~/Desktop/lobe_id_lego_block $ tree -L 2
.
`-- dataset1
|-- Lego1x1
|-- Lego1x2
|-- Lego1x4
|-- Lego2x2
|-- Lego2x3
|-- Lego2x4
|-- LegoTech
|-- NonLego
`-- None
上の構成はこうすればできます。
cd # 行き先をかかなければhome directoryにいけて便利ですね
cd Desktop
mkdir lobe_lego_block_id # これを今回のworking directoryとします
cd lobe_lego_block_id
mkdir dataset1 # あとでまとめて移動できるように親フォルダを作っておきます
cd dataset1 # この下に全部作ります
mkdir Lego1x1 Lego1x2 Lego1x4 Lego2x2 Lego2x3 Lego2x4 LegoTech NonLego None
写真を順に撮っていく
撮影するブロックの種類に合わせて出力先をオプションargumentで与え、buildDatasets.pyを走らせます。kボタンで撮影していきます。ブロックは45度ずつ回転させながらいろいろな向きで撮りました。今回は視野のほぼ中央になるように、また、背景には暗い色のものを用いました。
cd lobe_lego_block_id
# buildDatasets.pyはこのdirectoryにあるとします。
python3 buildDatasets.py --output ./dataset1/Lego1x1
# Lego1x1ブロックの撮影をします。qキーで終了。
python3 buildDatasets.py --output ./dataset1/Lego1x2
# Lego1x2ブロックの撮影をします。qキーで終了。
...

という具合につづけていきます。dataset1の中にあるどのフォルダにも00000.jpgから始まるファイルが複数入っているはずです。
dataset1フォルダをlobeのあるパソコンに転送
dataset1フォルダをパソコンにコピーします。USBドライブ、WinSCPなどのソフト、コマンドラインからSCPコマンド、どの方法でもいいので、lobeのあるパソコンにdataset1フォルダを持ち込みます。
Microsoft lobeで学習
lobeを立ち上げ、New Projectをクリックします。
左上の入力欄にプロジェクト名を入れましょう。たとえばlego-dataset1。
Labelを選択して、右上のImportをクリックします。
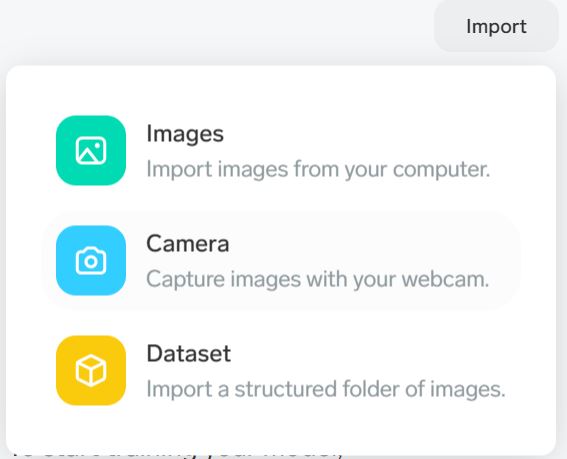
Datasetをクリック。
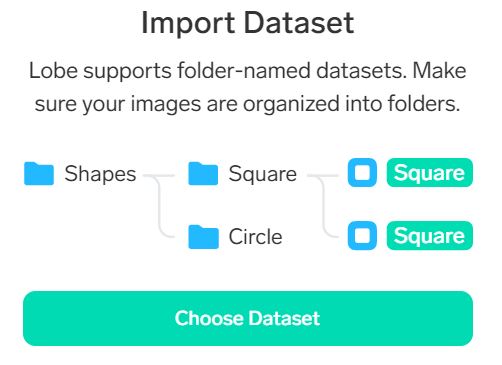
Choose Datasetをクリック。フォルダ選択ウインドウが開くので、dataset1フォルダを選択。
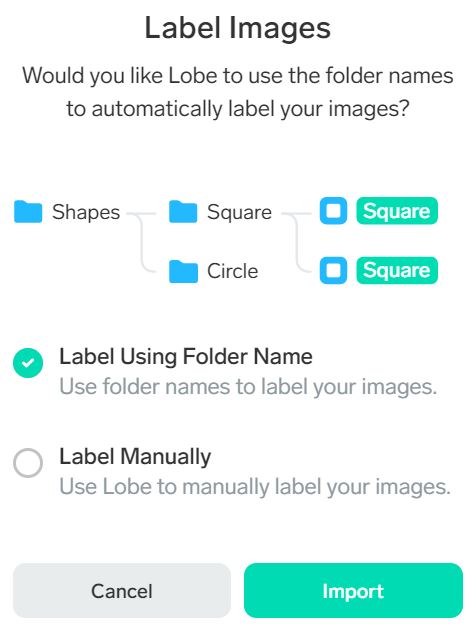
フォルダの名前がラベルになっているので、”Label Using Folder Name”が選択されている状態でImportを押すだけ。簡単です。(このために上のフォルダ構造の準備をしたのです)
Importが終わるとそのままTrainingが始まります。しばらく待ちます。Trainingが完了すると予測とラベルとをどこまで合わせることができたかが表示されます。
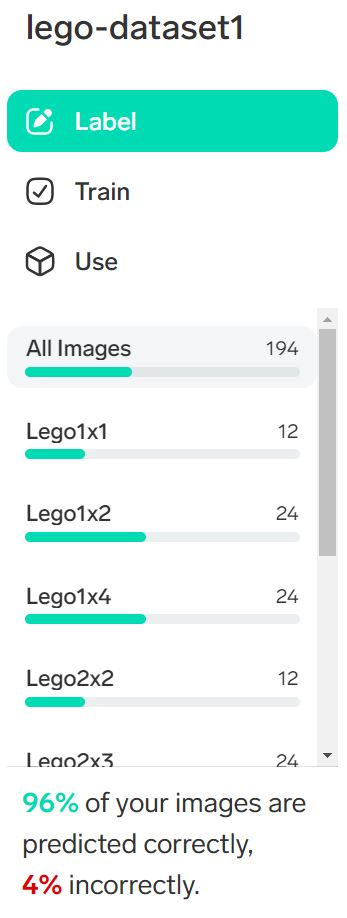
左にあるTrainをクリックすると、ラベルごとの合致率をみることができます。
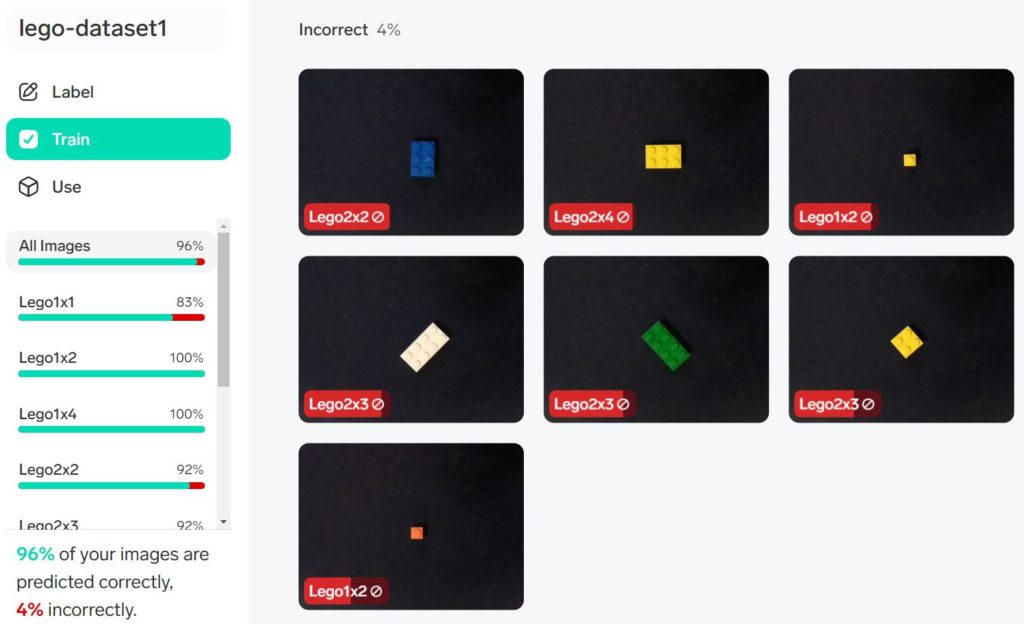
Incorrectのとして表示される画像は、構築されたモデルでの予測がラベルと合致しなかったものです。赤色のラベル名の上にカーソルを持っていくと、二番目、三番目の候補に上がったラベル名が表示されます。これが正しい、というものをクリックしてみてください。すぐにそれが正しくなるようにモデルの修正が始まります。

ここで重要なのは、あるものに正しいラベルを与えるようにモデルを修正することによって、これまで正しく予測されていたものの予測が間違ったものになる可能性があることです。しばらくいろいろ試してみてください。もともとの正解率よりも上回れば、それでよしとしたほうがいいかもしれません。正解が100%になるまでがんばることにはあまり意味がありません。ここでの正解率は限られた数の、train set内の画像に対するものなので、むしろ少し間違えるぐらいのほうが実際の分類では好成績がでる可能性もあります。
最初の正解率があまりに低い場合には、ラベルが間違っていないか確認したり(フォルダ名に対応した画像以外が入ったりしていないか)、写真の背景を統一してみたりしていろいろ試してみてください。さらに画像を追加したり、うまく判定されないものを除いたりしながら修正を試みることもできます。
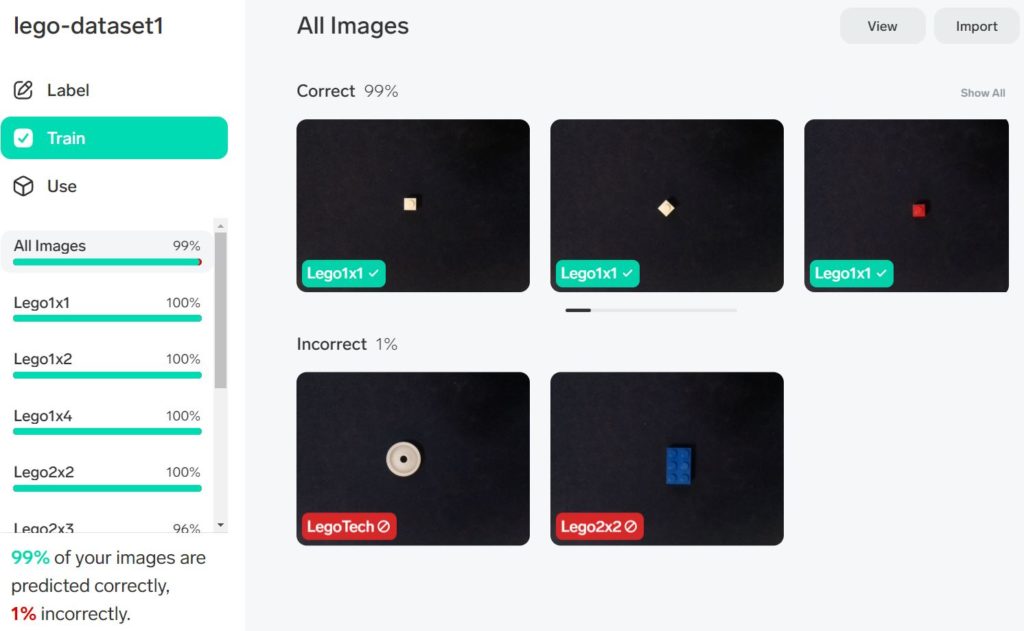
今回はこの段階でモデルを出力することにします。
modelをexport
左にある項目からUseを選びます。
右に表示されるImages|Camera|ExportからExportを選択します。

TensorFlow Liteをクリックします。出力先を選ぶダイアローグが出ますので、出力先を指定します。

Optimize & Exportをクリックします。しばらく時間がかかります。完了したらDoneをクリックします。
出力先には”lego-dataset1 TFLite”という名前のフォルダができてきているはずです。フォルダ名にスペースが入ってしまっているので、アンダースコア(半角で!)に変更しておきます。=> ”lego-dataset1_TFLite”
フォルダ名の変更ができたら、このフォルダごとRaspberry pi側にコピーします。今回の作業フォルダ、lobe_lego_block_idの中にコピーしておきます。
分類プログラムを動かしてみる
分類のためのコード、idLegoBlock.pyとmy_tflite_example.pyを作業directory、lobe_lego_block_idの中にコピーしておきます。
作業directory以下の構造は、以下のようになっています。
pison@3Ap1:~/Desktop/lobe_id_lego_block $ tree -L 2
.
|-- buildDatasets.py
|-- dataset1
| |-- Lego1x1
| |-- Lego1x2
| |-- Lego1x4
| |-- Lego2x2
| |-- Lego2x3
| |-- Lego2x4
| |-- LegoTech
| |-- NonLego
| `-- None
|-- idLegoBlock.py
|-- lego-dataset1_TFLite
| |-- example
| |-- labels.txt
| |-- saved_model.tflite
| `-- signature.json
`-- my_tflite_example.py
作業directoryに移動して、idLegoBlock.pyを走らせます。
cd lobe_lego_block_id
python3 idLegoBlock.py --model_dir ./lego-dataset1_TFLite
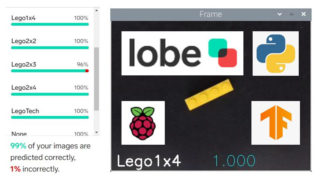
カメラからの画像を表示するウインドウが開きます。視野の中央にブロックを置くと、分類結果とconfidence levelが表示されます。またコマンドラインにはconfidence levelが高いほうから順に、すべてのラベルについての結果が表示されるようにしてあります。
使ってみて
lobeを使って機械学習に触れてみました。とっつきにくい部分を見事にブラックボックス化して一通りやってみることができるのは素晴らしいと思います。こうやって技術が一般化して当たり前になっていくんですね。今回の材料ではかなりいい成績がでます。2×3のブロックのみ、2×4として判定されてしまうことがあり、光の加減なのか何なのか、少しブロックの傾きを変えるとうまくいったりいかなかったり、色による違いもあるようなないような、うまい説明がみつかりませんが、簡単に見つかる説明で筋が通るようなものではないところに機械学習での分類のすごみがあるわけで、直接研究に携わって発展させたり技術を公開してくれている人たちには尊敬の念しかありません。以下、今回の結果のいくつかを示します。またほかの材料でも試してみたいと思っています。みんさんもぜひお試しください。
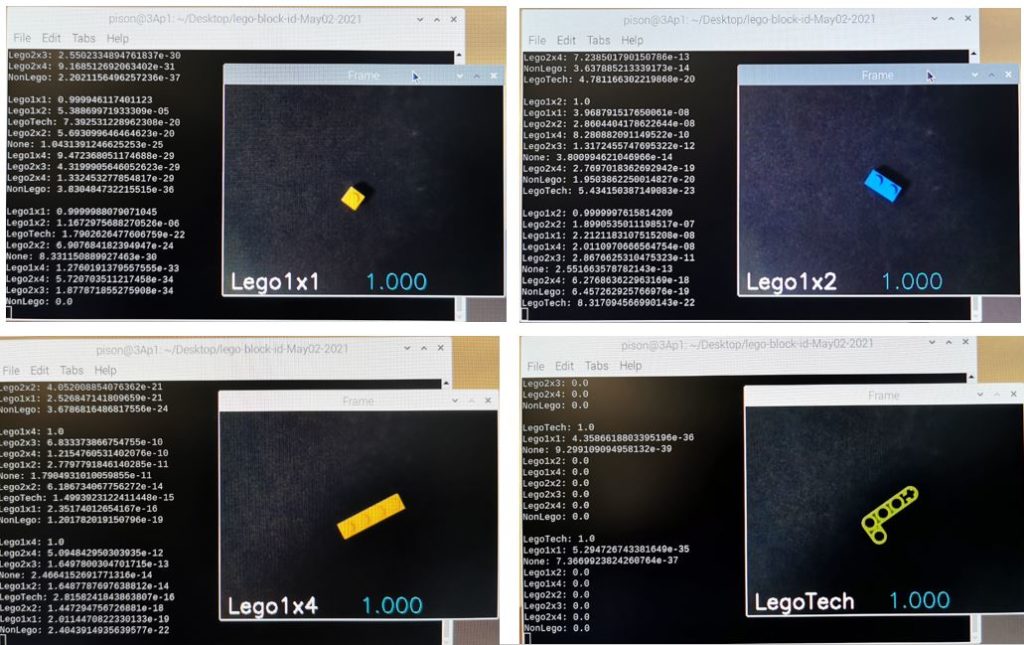
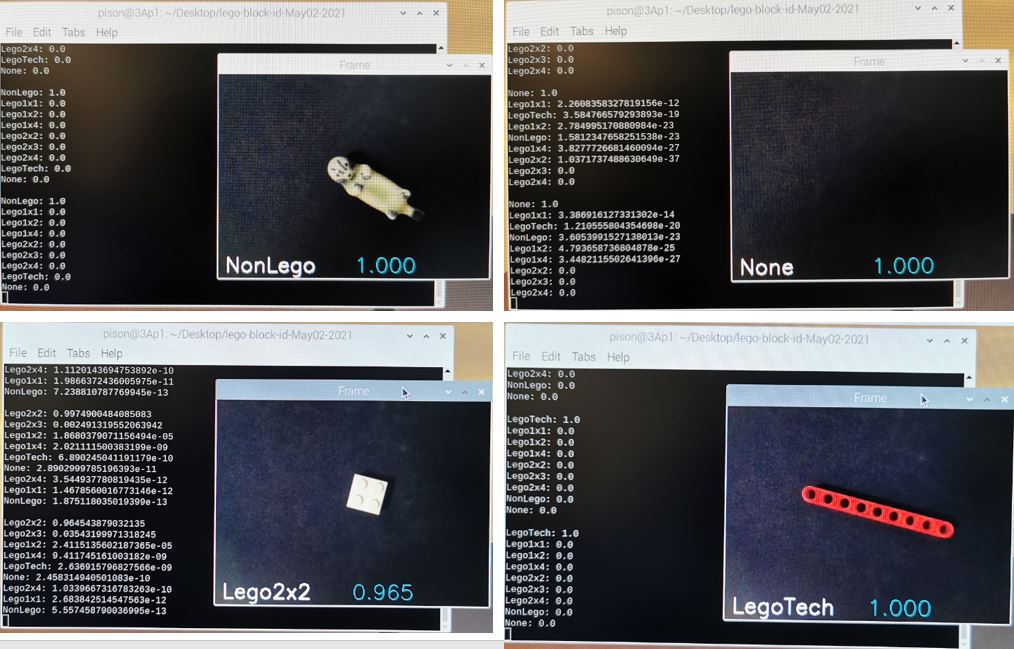
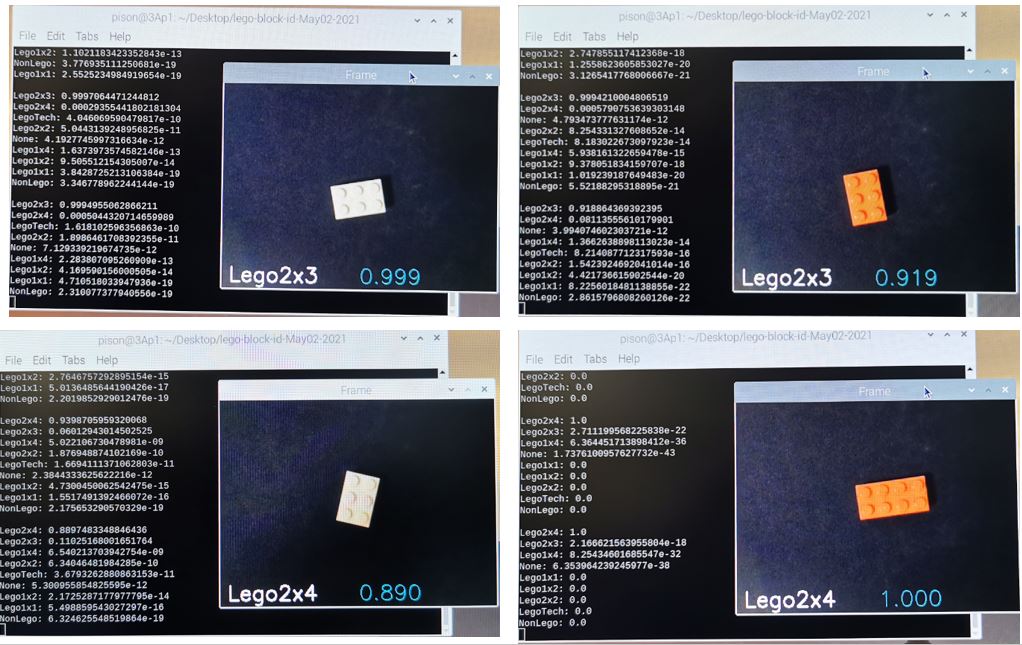
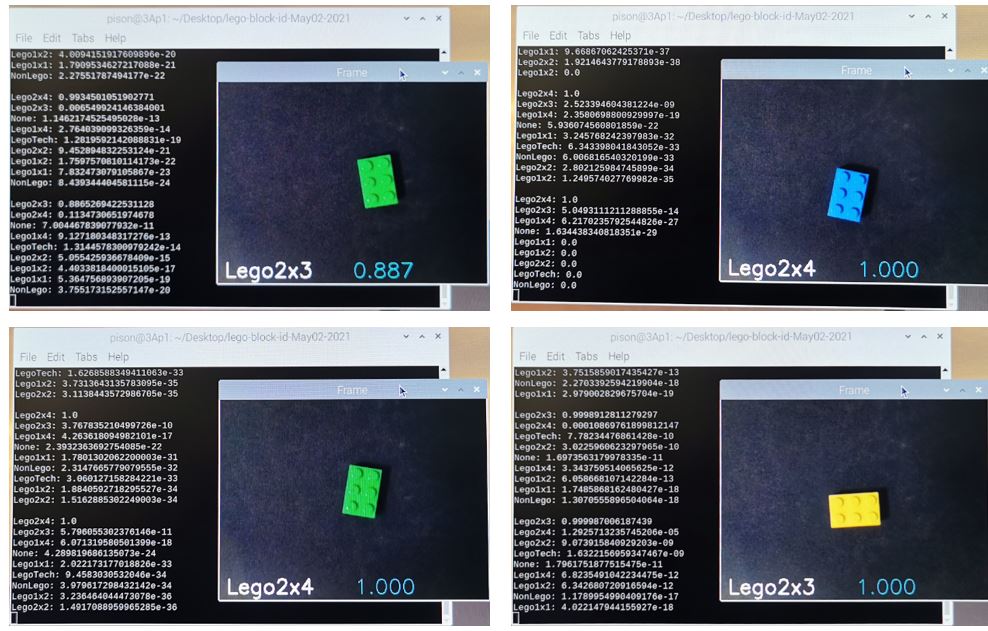
今回使用したコード
今回の記事で用いたコード、
- buildDatasets.py
- idLegoBlock.py
- my_tflite_example.py
は、GitHubに置いておきました。興味のある方はご参照ください。
my_tflite_example.pyについて
lobeからtflite用にモデルをexportした時に得られるフォルダは、次のような構造になっています。
pison@3Ap1:~/Desktop/lobe_id_lego_block/lego-dataset1_TFLite $ tree
.
|-- example
| |-- README.md
| |-- requirements.txt
| `-- tflite_example.py
|-- labels.txt
|-- saved_model.tflite
`-- signature.json
exampleフォルダの中にあるtflite_example.pyが試しに判定してみるためのコードです。このコードの位置から見ると、モデルファイルsaved_mode.tfliteは一階層上にあります。tflite_exampe.pyでは、常に一階層上にモデルファイルがあることを期待するようにコードが書かれており、これにもう少し自由度を与えるためにコードの一部を変更してmy_tflite_example.pyとしました。また、今回の記事では判定コードを別に作り(idLegoBlock.py)、そのなかからmy_tflite_example.pyを呼び出して使っています。
変更箇所は以下の一か所です。
class TFLiteModel:
def __init__(self, model_dir) -> None:
"""Method to get name of model file. Assumes model is in the parent directory for script."""
with open(os.path.join(model_dir, "signature.json"), "r") as f:
self.signature = json.load(f)
# ===== my edit (1) May02, 2021, ms ===== ここです
# self.model_file = "../" + self.signature.get("filename")
self.model_file = os.path.join(model_dir, self.signature.get("filename"))
# =================================== end of my edit (1)
...
references
- How to build a custom face recognition dataset (1)
- pip install OpenCV (2)
- python quick start (TensorFlow Lite) (3)