Hayabusa2情報表示板
なんで作ったの?
バス到着情報表示板というのを作ったとき、ボタンで表示するものを切り替えられるようにしておきました。その記事の中で、
青ボタンは、はやぶさ2の地球までの距離(このページからweb scrapingできた)を表示させるために使おうと思ったのですが、Raspberry pi zero wではjava scriptの実行が遅いのかなんなのか、web scrapingがうまくいかず (Raspberry pi 3Bではできるんです) 、どうしようかと思案中です。別のRaspberry pi (3B)に取らせてpi zero wに送り込むか、あるいはpi zeroを3Bに置き換えるか。
と書いたんですが、あのあとずっと考えていて、どうしてもはやぶさ2の地球までの距離を表示したいと思い、本日、ついになんとかなりましたので、記事にします。(粘り勝ち)
なにをするもの?
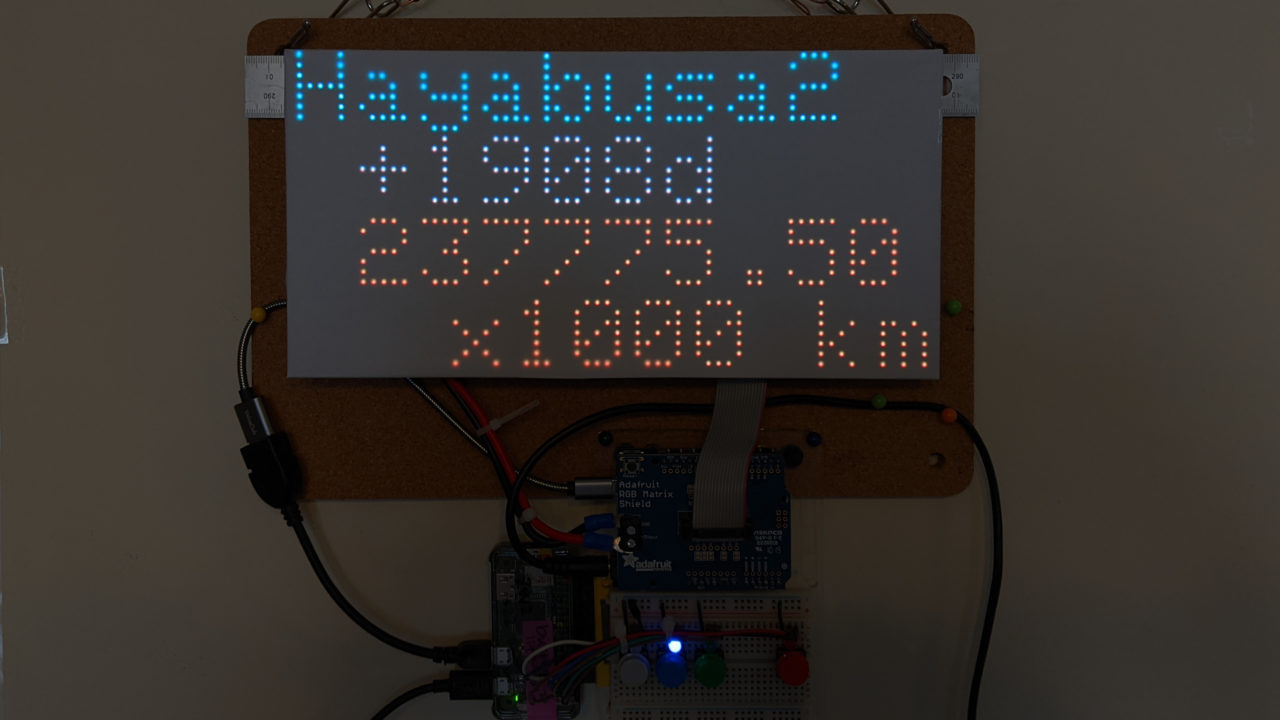
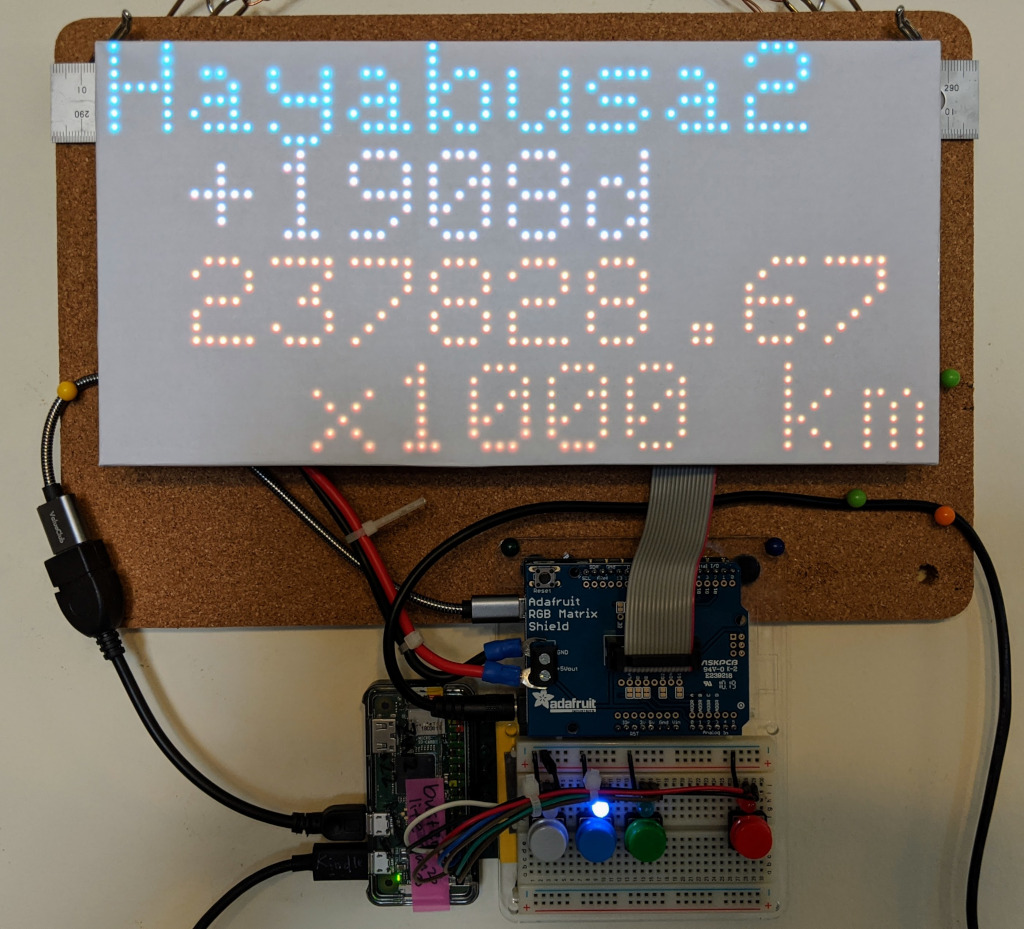
はやぶさ2の、打ち上げからの時間(days)と、地球までの距離をHayabusa2 Projectのページから取得(web scraping)してLED matrixに表示するというものです。Web pageでは1秒ごとに更新されていて、いかにものすごい速さで”はやぶさ2”が飛んでいるのかを感じることができます。javascriptが動いて1秒ごとの更新をしているようなのですが、その仕組みがどうなっているのか、よくわかりません。家の表示板でも1秒ごとの更新ができたらカッコいいんですが、1秒ごとにwebまで取りに行くのも申し訳ありませんし(実際処理に1秒以上時間がかかって何をしているのかよくわからなくなる)、javascriptの部分だけもらってやってみる力もないし(できたらいいんですが)、あとどのぐらいあるのかな、がわかればいいので、30分に一度、web scrapingするようにしました。
どういう仕組み?
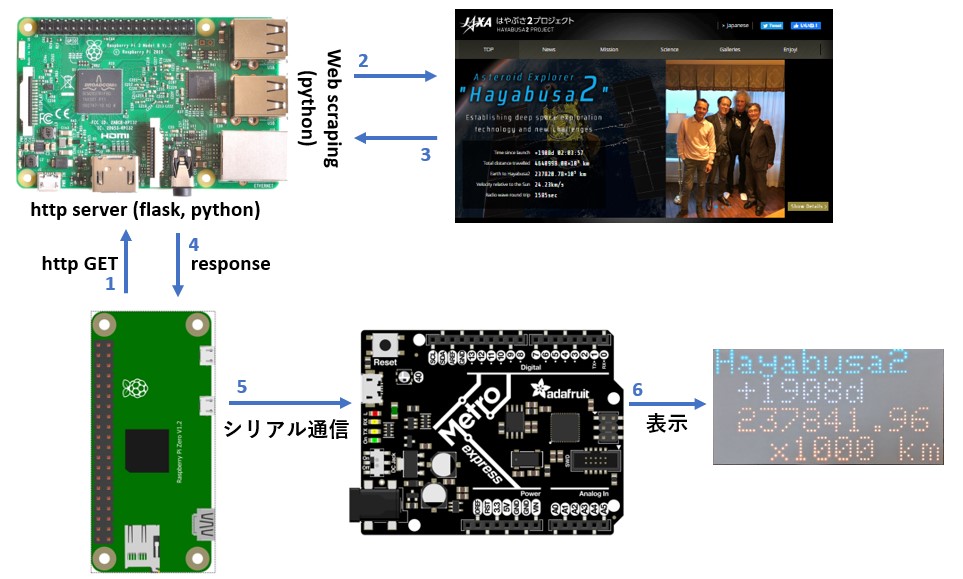
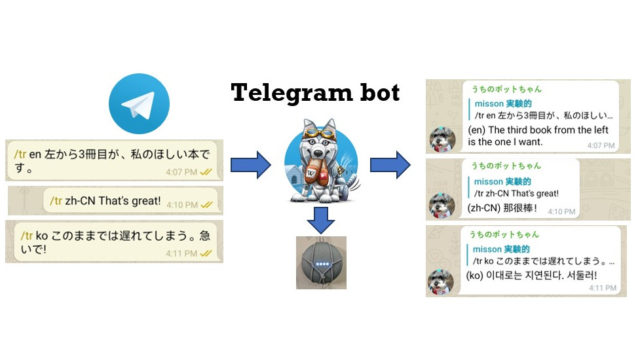
Raspberry pi zero w(二号機)が必要な時にRaspberry pi 3B(二号機)に情報とってきてリクエストをします(1)。頼まれたRaspberry pi 3Bは、Hayabusa2 projectのページを取得して(2,3)、javascriptが走るのを待ち、日数と距離のデータをhtmlファイルから抜き出してRaspi zero wに返信します(4)。あとはバス情報表示板のときと同じく表示内容をシリアル通信でArduinoに伝え(5)、LED matrixに表示がでる(6)というわけです。
なんで二台もRaspberry piがいるの?と思われるかたもいるかもしれません。理由は簡単で、pi zero wではweb scrapingに時間がかかりすぎるからです。何度か試したのですが、30秒程度で取れてくることもあれば、数分かかってしまうこともある。ばらつきがあまりに大きく、無理です、とpi zeroが言っているように思えたので、それなら、兄貴にやってもらうか、ということでweb scrapingの部分は他の仕事で常時稼働している兄貴分の3Bにやってもらうことにしました。いっそのことpi zeroのところを3Bに替えたら?とも思いましたが、バス情報の取得ではpi zeroがうまく動いていますし(小さいのががんばってるのは尊重したい)、二台のRaspberry piにやり取りさせて一つのことをするのもいいかな、それにどうすればできるのか、を考えるのも面白そうだったので、今回のような仕組みにしました。
使っている技(わざ)
興味のある方は、ここに出てくる文や単語をGoogle検索してさらに調べてみてください。
- flaskで簡単なhttpレスポンスサーバーを作る
- pythonでweb scrapingする
- httpで2台のRaspberry piにやりとりさせる
作り方
材料
- Web scrapingさせるためのRaspberry pi 3Bと、あとはバス情報表示板の記事を参照。
code
Raspi 3B側:flaskの仕事部分
from flask import Flask
from flask import jsonify
# === flask server ===
app = Flask(__name__)
app.config['JSON_AS_ASCII'] = False
@app.route('/haya2')
def haya2():
# get time_since_launch, earth_to_hayabusa from web
time_since_launch, earth_to_hayabusa = getHaya2Data()
return_dict = {'time_since_launch': time_since_launch,
'earth_to_hayabusa': earth_to_hayabusa}
return jsonify(return_dict)
if __name__ == "__main__":
app.run(host='0.0.0.0', port=8080, debug=True)
getHaya2Data()関数からの返り値をdictにいれてjsonify()でレスポンスとして返します。6行目はそのままではflaskはasciiで文字を返してしまうとのことで、False設定しています。これでutf-8がそのまま通るようです。
Raspi 3B側:web scraping部分
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
# === web scraping function ===
def getHaya2Data():
# optionsを入れる入れ物。
options = Options()
# Headless設定はこうする
options.headless = True
# Headless browser起動
driver = webdriver.Chrome('/usr/lib/chromium-browser/chromedriver', options=options)
print('implicitly_wait for 10 seconds from now.')
driver.implicitly_wait(10)
# browser access
driver.get("http://www.hayabusa2.jaxa.jp/en/")
print('sleep 5 seconds from now.')
time.sleep(5)
# encode page source
html = driver.page_source.encode('utf-8')
# BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
# table parsing
time_since_launch = "+0d"
earth_to_hayabusa = "0.00"
# get a table
table = soup.findAll("table")[0]
tbody = table.find("tbody")
trs = tbody.find_all("tr")
for tr in trs:
th = tr.find("th")
td = tr.find("td")
# get only
# Time since launch
# and
# Earth to Hayabusa2
if th.text == "Time since launch":
time_since_launch = td.text.split(' ')[0]
print(time_since_launch)
elif th.text == "Earth to Hayabusa2":
earth_to_hayabusa = td.text.split('×')[0]
print(earth_to_hayabusa) # wow! × is not x!!!
# quit browser
driver.quit()
return time_since_launch, earth_to_hayabusa
15, 19行目の待ちをなくしたり短くしすぎたりするとうまくうごかない。マシンパワーによると思われる。
Raspi zero w側:Raspi 3Bに頼む部分
import json
import urllib.request
# ref: https://requests.readthedocs.io/projects/requests-html/en/latest/
def getDataFromWeb():
# web scraping is done on 3B2
url = 'http://192.168.XXX.YYY:8080/haya2' # Raspi 3Bでflaskが動いている
req = urllib.request.Request(url, method='GET')
with urllib.request.urlopen(req) as res:
body = res.read() # bodyはbytes
decoded_body = body.decode('utf8') # これでdecoded_bodyはstrになる
resp = json.loads(decoded_body)
print('this is resp:', resp)
time_since_launch = resp['time_since_launch']
earth_to_hayabusa = resp['earth_to_hayabusa']
return time_since_launch, earth_to_hayabusa
8行目が兄貴分のRaspi 3Bで動いているflaskでのサーバー上のあて先です。どちらのRaspiも同じLAN内においてあります。
with構文でresponseを扱うのはどこかで見つけて参考にしましたが、どこだったか忘れてしまいました。いろいろ調べてまず手こずるのが、bytes文字のdecodingです。webから飛んでくる情報はbytesなので、それをpythonで使える形にする必要があります。こういったことをwebで検索すると、python2とpython3との情報が錯そうしています。丁寧に両者の違いを解説してくれているところがあるはずなので、探して読んでみてください。私はpython3を主に使います。このコードもpython3で試しています。
使ってみて
30分に一度の更新なので、あんまりスピード感がありませんが、小数点のすぐ上が、1000キロであることを考えて、更新でどれだけ進んだのかを計算してみると、びっくりします。現時点では太陽までより遠いな、というところですが、これからどんどん近づいてくるのが楽しみです。x1000の部分がそのうちいらなくなるのでしょうか?カプセルを切り離すときのスピードもものすごいはず(じゃないとはやぶさ2自体が地球に落ちてきてしまう)なので、x1000はずっと残るのかも。いまは距離が減る方向に変化していますが、カプセルを地球に届けたあとは増加に転じるわけですね。いつまで情報提供がつづくかわかりませんが、じっと見守りたいとおもいます。
このあとの予定
できればHayabusa2 projectのページで動いているjavascriptを自分のところで動かすことができれば毎回scrapingしなくてもいいし、毎秒更新ではやさが実感できる。本家ページも毎秒情報をどこかからとっているとも思えないし、何かの計算式でだしていると勝手に想像しているのだが、どこかで実際の位置との補正もしているはずだし、どうなってるんだ?と気になっています。こうなったらJAXAに問い合わせてみるのがいいかもしれないですね。以前、相模原キャンパスに見学に行ったことがあるのですが、あの時にだれかにきいてみればよかった。
ということで、ひとまずやりたいことはできるようになったので、これ以上改変はしないかもしれません。が、急に何か思ついて面白いものができたら記事にします。
うらばなし
2020年の1月に、web scrapingの小手試しをしていたところ、突然Hayabusa2のweb pageにつながらなくなってしまった。げ。もしかしてblockされた?とはいえ、そんなに不自然な回数web接続をしたわけでもなく(1秒に100回とか)、普通に手動で、走らせては、エラー、コードを直しては走らせる、を数回繰り返しただけ。数日して普通につながるようになったのだが、単なる偶然?メンテ中だった?よくわかりませんが、web scrapingはサーバー側に迷惑をかけないように、また取得した情報の扱いには注意が必要です。