edge impulseで機械学習:リモコン忍者kikuzoに音認識(単語)させるための準備

今回できるようにしたいこと
これまでの二つの記事では、どちらも画像認識を扱いました。
- Microsoft lobeで機械学習:得られたtfliteモデルを使ってRaspberry pi上でLegoブロックの分類をする
- Teachable Machineで機械学習:Coral EdgeTPU+Raspberry piでハンドサインを認識させる
次は、音の認識もできるようになりたい。といいますのは、簡単なことばの認識ができれば、google assistantやIFTTTなど、外部の仕組みに頼らずに家の中だけで完結させられることがあるからです。(以前の記事、「Google Home MiniやAlexaに頼んで何かしてもらうときに考えること」参照)
今回、edge impulseを用いて音声認識のモデル構築を行い、忍者エージェントkikuzoの呼び出し関連コマンド、”きくぞう”、”さがってよい”、ならびに、”てれび”、”えあこん”が認識されるようにします。(リモコン忍者エージェントの工作は、別記事にする予定です)
基本的に本家が提供しているResponding to your voiceのページに従っていますが、少々interfaceが現行のものと違うところもあって戸惑いました。この記事のscreen shotたちもいずれ現行のものとはずれていく可能性がありますので、お早めにお召し上がりください。
lobe, teachable machine, edge impulse?
なぜedge impulse?
音声データを機械学習の入力として使うには、収集とデータの切り出し、入力にふさわしい形への前処理(FFTやMFCC)が必要で、ちょっと試してみたいという程度の動機では超えづらい高さの壁を持つのが音声データです。edge impulseはこのあたりの敷居を見事に下げてくれます。
- 自分でやるにはかなり面倒な、固定長フレームの切り出しをグラフィカル表示とともにわかりやすく行うことができる。
- 切り出しフレームをランダムにshiftさせた、より実践を考慮した切り出しが可能
- 切り出したデータの処理も数クリックで完了(FFT: Fast Fourier Transformation -> MFCC:Mel Frequency Cepstral Coefficients)
- mobile phoneを音声入力デバイスとして使うことができ、データ収集(録音、アップロード)が簡単
さらに、今回は音を拾って判定をする部分を最終的にはArduino nano 33 BLE sense上で実行させ、edge computingを実感したい。Edge impulseは以下のものも提供してくれるので、いたれりつくせりです。
- 対応device用の実行プログラム(トレーニングモデルを即座に試すことができる)
- Arduino、C++ライブラリ
- kerasを使ったpython code (network structure, parameters)
LobeやTeachable machineのもう少し向こう側を提供してくれるのがedge impulseです。名前が示す通り、edge computingが主目的です。
道草:lobeで音声認識できるか?
Microsoft lobeでは、画像データが主な対象になっていて、実際、”Use”の画面では”Images”, “Camera”でのテストをするようになっていることからもそれがうかがえます。

しかし、画像データも便宜上”画像”と呼んでいるだけで、中身は点データの集まりです。音のデータも瞬間瞬間の点データならば、もしかして音のデータも入力として使える?と考えるのは自然です。しかし、
- 音データのファイル形式そのものをlobeが受け付けない
- ことばのデータは長さが一意に定まらない場合の方が多い
二つ目は重要です。たとえば、”たいやき”と、”みたらしだんご”とでは、言うのにかかる時間が異なります。現在の主な手法では、あるきまった長さの枠をデータに当てはめて、その部分の特徴を見るという方法がとられるので、例えばトレーニングデータを用意する場合、録音データの中から、あらかじめ決めておいた一定の長さの枠で”たいやき”と”みたらしだんご”を切り出していく必要があります。自力でこの部分を行う場合、ここが難所です。
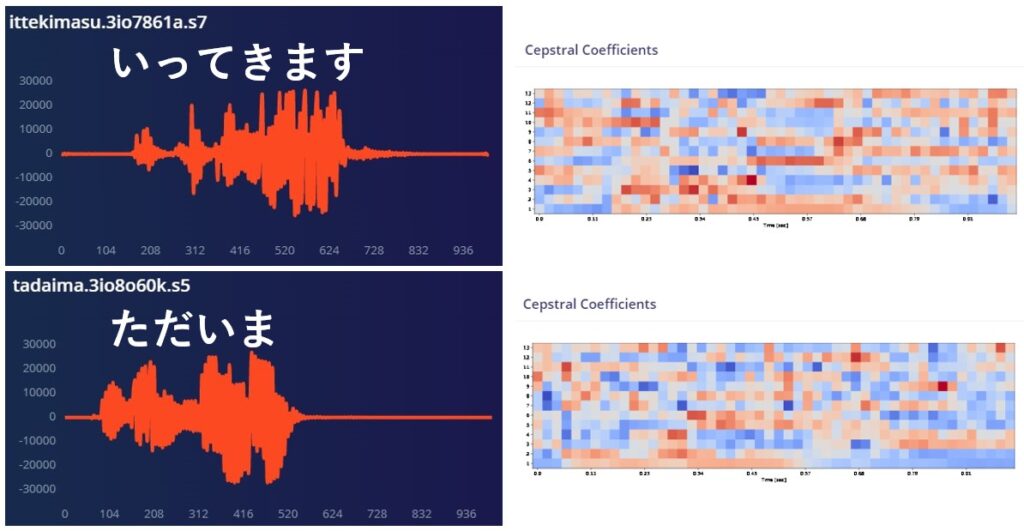
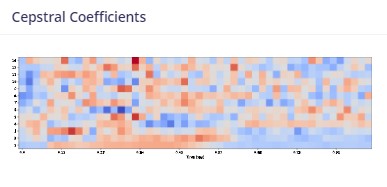
音のデータは、スピーカーのブルブル度合いを時間方向に対して記録してあるわけですが、そのままだとどうしても特徴が出にくい。下の例は”いってきます”と”ただいま”のものです。左側が時間軸に対するスピーカーのブルブル度合い(wave data)、右側は特徴を捉えるための音声学的な処理(FFT->Mel Filter Bank->DCT、すなわーち、時間軸上のブルブルを周波数とpowerに解釈しなおし->ヒトの耳への感度を勘案したフィルタを通して眺めて->とびとびのエネルギー指標に置き換え <- 知ったかぶりしてます🙇)をして表示したものです。どうだ、といわれてもアレだと思いますが、なんとなくでも右側の方が特徴を持った入力データとして便利な気がしませんか?左は特徴を述べよ、言われたらまとめづらい、右は例えば濃い赤の位置を追うだけでも特徴を言うことができます(気はする)。あと、右側は決まった大きさのタイル状(13 x 50)にまとまっていて、これはミソです。(入力レイヤーのnode数が少なくて済む)
と、ここまで来ると、え、右側を絵、画像だと思えば、音のデータもlobeに入力できるんじゃない?と思ったアナタ!すごい!その通り。たとえばneural networkにとっては、元が画像だろうが、音だろうが、加速度センサーからのデータだろうが、いったん決まった形の点の集合データになってしまえば何でも来い!なんです。Lobeの場合、上に書いた音データの処理までは面倒をみてくれないだけで、画像みたいなデータにした音データなら扱ってくれるはずです。
ということで、lobeで音声認識できるか?に対する私のこたえは、音を画像にすればできる、です。これは大変面白そうな課題なのですが、今回は上に書いた理由により、edge impulseで行きます。(試していないんですが、上のケースなら13×50ピクセルの絵として音のデータを作り替えることができるならlobeに流し込めるはずです。あるいはmatplotlibなどでグラフ(jpg画像)として保存させてもいいかもしれない。これ面白そうなテーマですね)
道草:Teachable MachineにもSoundsっていうのがあるんですが
ですね。Teachable Machine Tutorial: Snap, Clap, Whistleっていう指南ページもあります。しかし、今回は最終的に音の収集と判定部分をArduino nano 33 BLE senseやESP-Eyeのような小さなデバイスにのせたいと思っているので、そのあたりまでうまくカバーしてくれるedge impulseで試してみることにしました。
さらに寄り道:音声認識でまず考えること
今回は単語そのものを一つの音の塊として認識することを目指しています。どういうことかというと、”きくぞう”を認識させるというのは、”きくぞう”という一連の音すべてをひとまとまりとして認識させるということで、”き”、”く”、”ぞ”、”う”を個別に認識させてそれがこの順で得られたとき、いまのは”きくぞう”だと認識することとは異なります。”ものすごく鼻のきく象がいました”という文の中にある”きく象”の部分が今回の”きくぞう”ではない、というような前後関係を考慮した単語の認識も、これまた別トピックとなります。
今回は私の言う”きくぞう”を認識させることが目的なので、サンプルとしては私の声のみを収集しました。もし、だれが言っても”きくぞう”と認識させるようにしたいならば、できるだけ大勢のひとの”きくぞう”を収集し、すべてに同じラベルを与えてトレーニングする必要があります。(いくつかの別ラベルにしておいて最終段階で一つにまとめるという手もあります)Tutorialで使われている”hello world”の認識は、この路線でたくさんの人の声を集めています。
例えば認識させたい単語が二つあるとき、その二つだけでトレーニングを行うと、その二つ以外が聞こえた時、あるいは何も聞こえていない時にもどちらかへの分類が行われてしまうため、全く思ったような判別器を得ることができません。”何か”を認識させるためには、積極的に”何かではないもの”たちを用意する必要があります。そのためのサンプルが、カウンターサンプルです。今回のnoise、unknownがそれにあたります。
単語そのものを一つの音の塊として認識するためには、データ窓の広さをそれにあわせてとる必要があります。今回はどれも短い単語なので、1秒(1000 ms)を枠の長さにとりました。もし単語ではなく、雨の降る音やバスの通過音などを認識させたいならば、もっと短い枠でも特徴が捉えられる可能性があります。
edge impulseを使う(ここからものすごく長いです)
まずはhttps://www.edgeimpulse.com/を開き、sign upしてアカウントを作成しておきます。ログインします。
今回は短い単語の認識(私の声)がテーマです。基本的にというか、ほぼそのままdocumentationのtutorialsにあるResponding to your voiceに従います。
流れは、
- 音のデータを集める
- 一定長の枠で音データを切り出す
- 特徴量をうまく表現し、かつneural networkに流し込める形にデータを処理する
- トレーニングしてモデルを得る
- deviceにモデルと判定の仕組みをのせて遊ぶ
です。
それでは参りましょう。
projectを作る
edge impulseのページを開いてloginします。
Create new projectボタンをクリック。
名前を付けて、Developerのほうのラジオボタンが選ばれているのを見ながら、Create new projectをクリック。
今回は音データに挑戦しますので、Audioをクリック。
次なんですが、development boardは後から登録できますし、これからデータを集めるのでimport existing dataも違います、tutorialsもすでに観た、あるいは後で観ることにして、Let’s get started!ボタンをクリック。
これでprojectのページが開きます。次へ行きましょう。
音のデータを集める
ページの真ん中の列に、これからの流れが表示されています。最初はAcquiring dataです。LET’S COLLECT SOME DATAをクリック。
どこからデータを取りますか、ってことなんですけど、今回はケータイを使います。マイクもあるし、あちこち動きながらサンプリングできますし。Show QR codeをクリックして表示されたQR codeでリンクに飛びましょう(ブラウザで開く)。
無事接続されるとコンピュータの方にその由、表示されますので、Get started!をクリック。
ケータイ側にも次のような表示がされますので、Collecting audio?をクリック。
マイクを使っていいですか、と来るので、Give access to the microphoneをクリック。

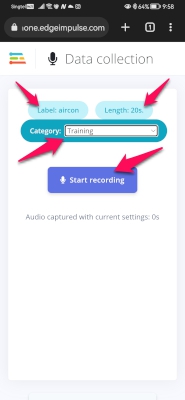
ここは重要です。まず、Labelのところには、今からとる音が何なのかを書きます。これがいわゆる正解名となりますので、あらかじめ音につけるラベルは決めておきましょう。タップすると入力窓がでますので、そこに書き込んでください。日本語文字で試したことがありませんが、半角アルファベットにしておいた方がいいと思います。Case(大文字小文字)にも注意して。
Lengthのところは録音時間です。好きな長さにします。あまり長いと飽きてきますので、今回は20秒としました。
Categoryですが、Trainingとしておきます。まずはTraining dataとしてデータを集め、切り出しが終わった後でTraining-Testを切りわけます。とにかくまずは音集めをしましょう。
入力が済んだらStart recordingをタップして録音を開始します。
えあこん、えあこん、と少しづつ言い方を変えたりしながら20秒間唱え続けます。あとで認識枠を1秒にとりますので、一秒でおさまる感じで唱えます。間に少しポーズをいれましょう。はたからは何をしているのだ、この人は、という感じになりますが、ケータイの向きや距離も変えながら無心で録音します。
録音が完了すると、edge impulseへ自動でアップロードされます。アップロードしましたよメッセージが画面に現れて消えます。
これをひたすら繰り返します。今回は、えあこん、てれび、きくぞう、さがってよい、さがれ、を録音していきました。さがってよい、と、さがれ、には同じラベルを付けてみました。二つとも同じものとして学習させるもくろみです。
ひたすら、と書きましたが、ひとまず20秒で5-6回にしました。このあと、1秒の枠での切り出しを行いますので、正味の音サンプル部分の合計は短くなります。ポイントは、どのラベルの分も大体同じぐらいの合計時間にすることです。今回は切り出し後の合計が1分ぐらいになるように録音を続けました。あるラベルのサンプルがほかのものより何倍もあったりすると認識に偏りが生じる可能性があります。このあたりもいろいろ試してみると発見があるかもしれません。
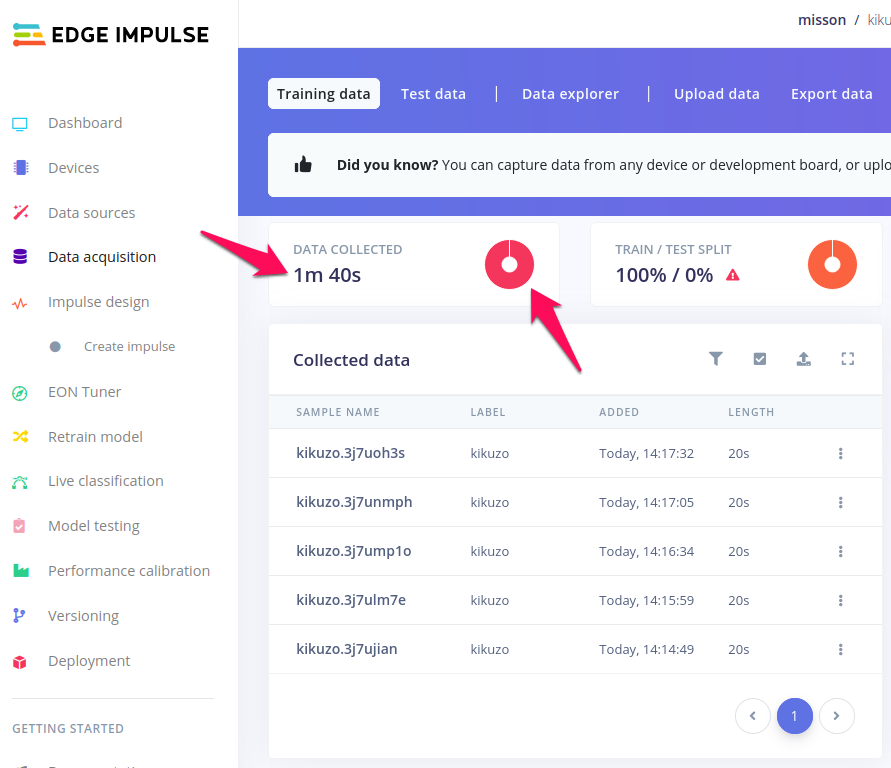
さて、パソコン画面に戻ってみてみると、アップロードした音の情報が反映されているはずです。下の図は、きくぞう、を20秒で5回録音したあとの様子です。DATA COLLECTEDのところに1m 40s (=100秒ですね)と表示されています。よこのドーナツは、いま一色ですが、ことなるラベルをアップロードするにつれ、割合が色分けで表示されていきます。バランスを見ながら、録音を追加しましょう。
音の切り出し
ここです。ここがedge impulseを使う理由の一つでもあります。今回の録音では、一つの録音に認識させたいことばを複数回含めました。一つ一つのファイルとして録音するより便利だったからです。
さて、機械学習で、入力がどのように判別機に入っていくのかを想像してみてください。imageの場合、一枚の写真ごと、movieの場合、データは時間軸方向に連続しているように見えますが、実際は1フレーム(一枚の写真)ごとに入力されていきます(fps, frame per secondという単位を聞いたことがあると思います)。どちらの場合も入力は一枚、あるいは1フレームというchunkとして、独立した塊の形になっています。
ところが、音声の場合は連続的にサンプリングが行われていて、一枚とか、1フレームといった区切りがありません。サンプリングは、実際一秒に16000回(これをsampling rateとかsampling frequencyといいます。defaultが16kHzです)という速さで行われるので、16000のうちの一つ一つは独立していてある意味フレームといってもいいのですが、一つでは16000分の1秒の音しか保持しておらず、特徴をつかむにはもっと大きな枠の塊を入力としたほうがよいということになります。(イントロクイズを知っているかたは、与えられる音があまりに短いとどの曲だかわからない、を思い出してください)
今回は、その、このぐらいなら意味を持つだろうという枠を1秒(1000ms)に固定します。短いことばならこの枠に入ります。この大きさの枠で、録音した20秒のサンプルからことばの発声の部分を切り出していきます。(ことばとことばの間の部分は捨てることになります)
まず、切り出したい20秒のサンプルを選択します。再生ボタンで聞いてみることができます。次に、右の ⁝ (縦の点点点、vertical ellipsisといいます) からSplit sampleを選びます。
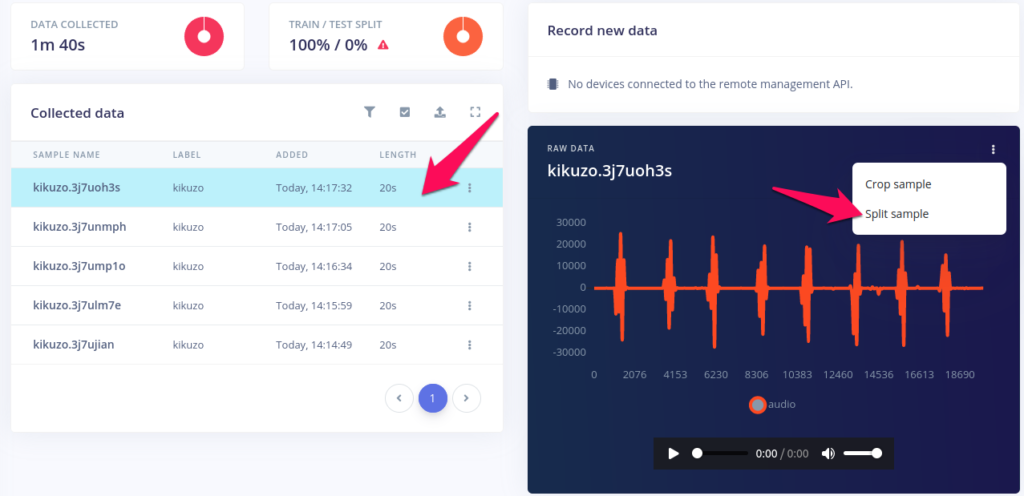
編集画面が現れます。まず、Set segment lengthのところ(1)が1000になっていることを確認。違う場合は1000を入力してApplyをクリック。
一つ一つの枠がきれいに発声部分をかこんでいるか見ていきます。枠は選択することができ(3)、その枠の部分だけを再生することもできます。目的の発声ではない音が選ばれていないことにも注意しましょう。もしそういう部分がある場合、その枠を選択してRemove segment(4)で枠どりを消すことができます。ここが選ばれていない、という場所がある場合には左上の+Add Segmentをクリックして枠を追加してください。
下の右(2)にSghift samplesというチェックボックスがありますのでチェックを入れておきます。これはわざと枠取りをずらすものです。実際の判定では、1秒の枠を重なりをもたせて少しづつずらしながらデータの入力がされていくので、目的の発声部分が必ずしも枠の中心にくるとは限りません。むしろ、こない場合の方が多いかもしれない。そこで、あえて少しずれた枠どりでデータを切りだし、それをtrainingに使うことで、実際の状況に近くしておこうという魂胆です。
最後にSplit(5)をクリックして編集を終えます。
ラベルごとのバランスをとる
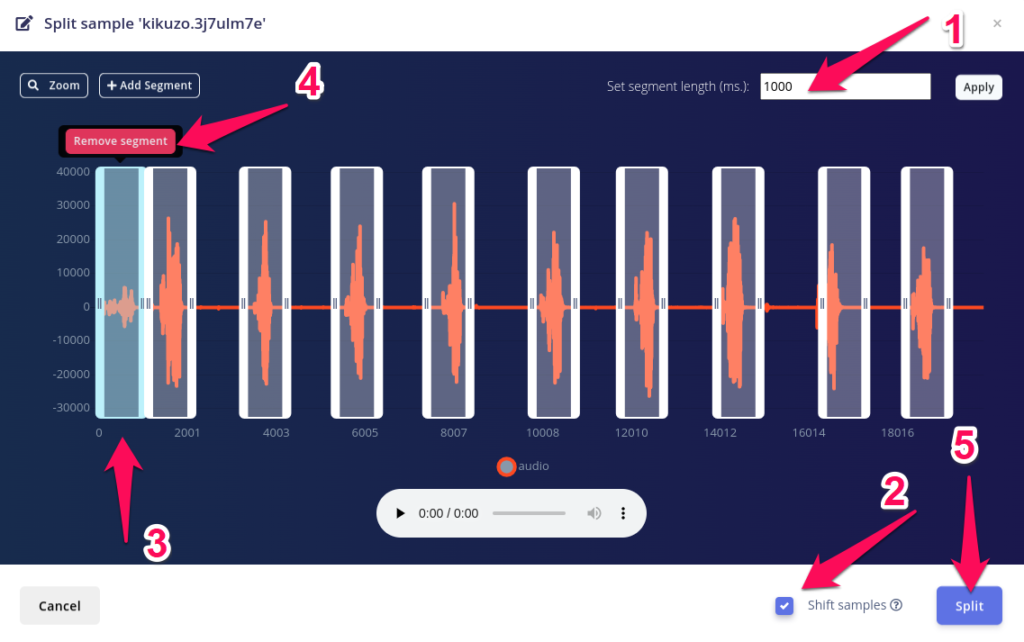
切り出しをせっせと進めていくにつれ、左のドーナツの切り分けが変化していくと思います。切り出したサンプル数はラベル間であまり偏りがないようにしておくのが基本です。ドーナツの切り分け具合を見ながら、足りないラベルの音を追加したりしてうまくバランスを取ってください。マウスカーソルをドーナツの上に持っていくとラベルに含まれるサンプルの合計時間が示されます。30秒分足りないな、と思ったら、あと30回そのことばを録音して切り出せばうまく埋め合わせできます。

バランスを見るもう一つの方法は、以下の通り。Sort, filterのアイコン(漏斗のマーク)をクリックすると、それぞれのラベルのサンプル数がカッコの中に表示されます。これを目安にすることができます。
counter sample(noise, unknown)の追加
ここまでで、ことばの音集めは完了したのですが、このままではうまく判定ができない可能性が高い。というのは、実際の使用においては、
- 音がまるでない、あるいは環境音のみがある状況
- 集めたことば以外の声が聞こえる状況
の二つが考えられますが、判定器は常に判定を試みますので、音がまるでないような状況でも強制的にどのことばに近いか、が結果として得られてしまいます。そこで、counter sampleたちを追加しておく必要があります。これは集めるのが非常にむずかしいので、先人たちが用意してくれているものを拝借することにしましょう(太感謝了!!)
データセットのダウンロード
このページにあるダウンロードリンクから、keywords2.zipファイルをとってunzipします。
こんなフォルダたちが含まれています。使うのはnoiseとunknownの中にあるファイルたちです。
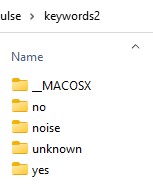
データ多すぎ!60秒分なら60個でいいんだけど
ですね。フォルダを開いてみると1500以上のファイルが入っているのがわかります。Keyword spottingのページに書いてあるように、それぞれ25分ぶん、1秒づつに区切ってあるとのこと(sampling rateは16kHz)。うーむ、いくらなんでも1500回きくぞう、という気にはなれませんでしたので、counter側を減らすことにしたい。自分のサンプルはだいたい60秒分集めたので、60個づつnoiseとunknownから拝借したい。でもどう選ぶ?
上から60個でもいいのですが、noiseの方にはいろいろなものの音が入っていますので、上から60個選んでは何らかのバイアスがかかってしまうかもしれない。テキトーに選びたい。判定がうまくいかず、やり直す場合にも再度テキトーに選びたい。自力で毎回テキトーというのも苦痛ですので、pythonにお願いすることにしてコードを書きました📃: fileSelector_v2.py GitHubに置いておきましたので、pythonが使える環境をお持ちの方は使ってみてください。使い方は、選びたいfileの入ったフォルダへのpathと選びたい個数を与えるだけです。current dirにnoise-selected-60のような名前のフォルダができてきて、その中にテキトー(ランダム)に選ばれたファイルがコピーされてきます。
# current dirにkeywords2があるとします。
python fileSelector_v2.py ./keywords2/noise 60
# curent dirにnoise-selected-60フォルダができてきます。(便利)
pythonに頼むにせよ、自力で選ぶにせよ、選んだファイルはnoise, unknownそれぞれ別々のフォルダーにいれておきます。(アップロードのとき、フォルダをえらんで、その中のファイルを選ぶことになります。あらかじめフォルダにまとめておけば、そのフォルダを選び、中身すべて、で簡単です)
noise, unknownをedge impulseへ上げる
選んだファイルをedge impulseへアップロードします。下の図にある、Upload data、あるいは箱から上向きの矢印が出たアイコンをクリックします。
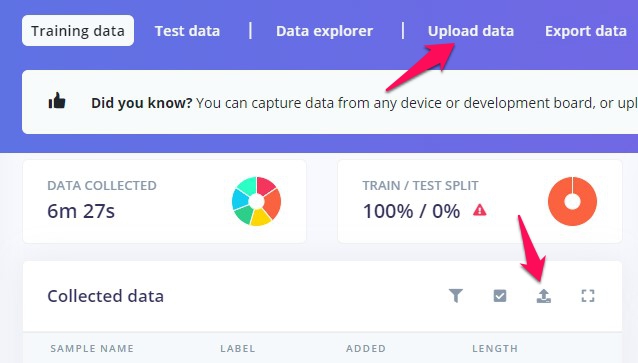
Upload into categoryはTraining、LabelのところはEnter labelを選んでlabel名を入力します。何度か書いていますが、Training-Testの切り分けはこの後行いますので、今はすべてTraining categoryとしておきます。一部がTest categoryに入ってしまっている、どうしよう、という場合、ご心配なく。Categoryの変更も後からできます(👉こんなときどうする集を見てください)
Choose Filesボタンをクリックします。
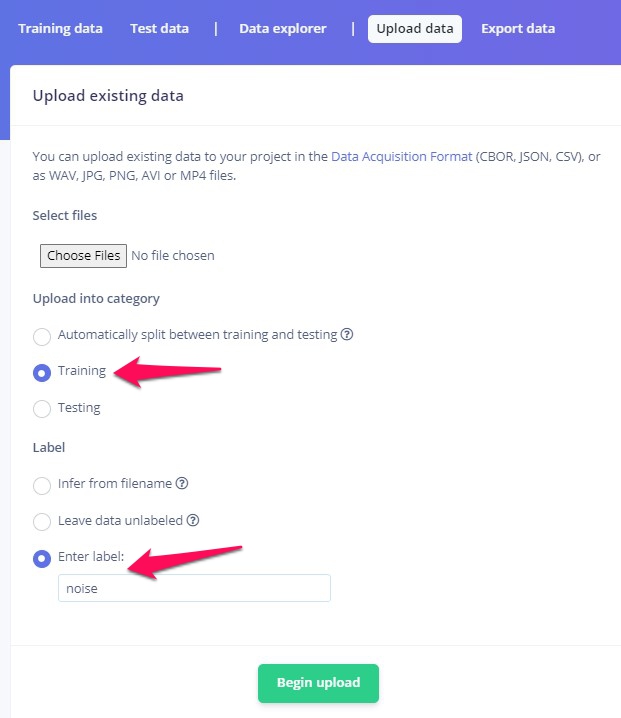
選択ウインドウが出ます。先ほど選んだファイルを入れておいたフォルダを選び、Openをクリック。
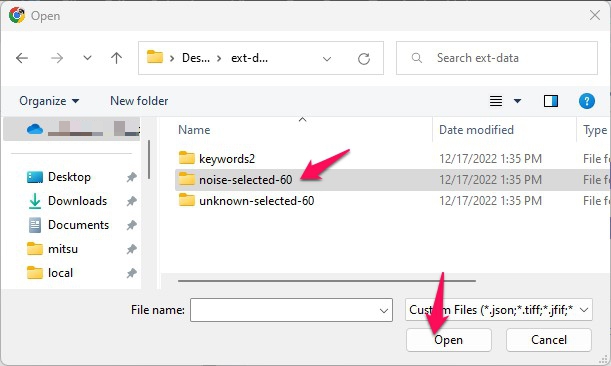
フォルダ内のファイルが見えます。全部選びます。どうやって?まず一つ選んで、Ctrl+A。最後にOpenをクリックします。
確かに自分の思っている数のファイルが選ばれたことを確認したら、
一番下にある緑色の、Begin uploadをクリックします。右側にログが流れます。Job completedと出たら完了。同様にunknownの方もアップロードします。
train-testの切り分け
右のドーナツを見てください。これまでデータはすべてTrainingの方へ入れてきましたので、下のようになっているはずです。そうなってないぞ、という方は、こんなときどうする集をみて、すべてTraining categoryへ振ってください。
右のドーナツのところにある小さな赤三角をクリックします。

現在のデータに関する要約が表示されます。ところで、Training dataとtesting dataってなんだ、ですが、集めたデータのうち、すべてを判定器(classifierと書かせてください、変換が面倒)のtrainingに使ってもいいのですが、できてきたclassifierの性能をテストする際に、classifierが知っているデータを使うのは少しunfairな気がしますね。だって、それでtrainingされたわけですから。(入試で過去問そのものを出す感じです)そこで、集めたデータの一部はtrainingには使わずに取り置きしておいて、それを使ってclassifierの性能をテストするという方法がとられます。Test dataはclassifierにとっては、お初にお目にかかりますデータなので、よりfairである、というわけです。なんで7割3割じゃいけないのかとか、一回だけ切り分けたものでいいのか、何度も切り分けてその都度性能を確かめた方がいいのではないかとか、そのような考えを持った方はスゴイ!もっと深入りしてください。でも今はedge impulseを使ってみよう、という記事なので、このあたりでご無礼つかまつりますことにしたてまつりますれば、云々。ということで先へ進みましょう。
一番下にある、Perform train/test splitをクリックします。
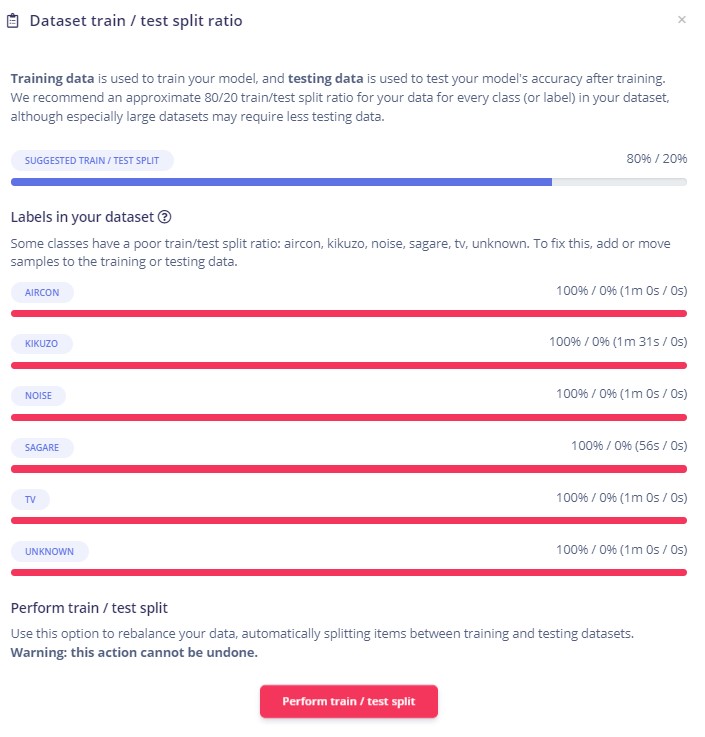
Train / test splitはよほどのおおごとであるらしく、次のようなメッセージが現れます。やり直しきかんけどええきゃ(名古屋弁)?当然こんなところで引き下がるわけにはいきませんので、Yes, perform the train / test splitを毅然とクリック。
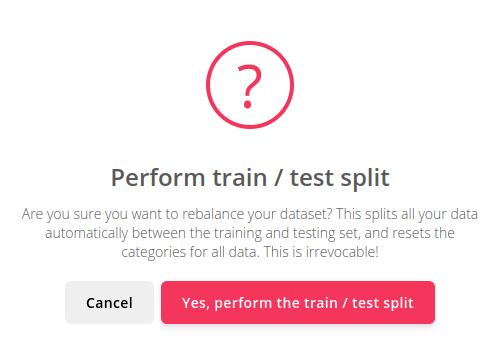
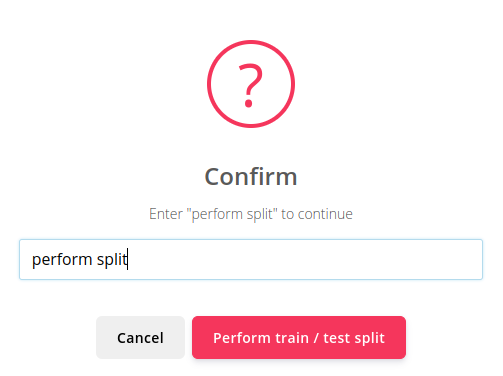
すると、次のメッセージが畳みかけます。ほんならperform splitってタイプしてちょ(まだ名古屋弁)。もちろんそうタイプします。(paformとか打たないように)それで、Perform train / test splitをクリック。
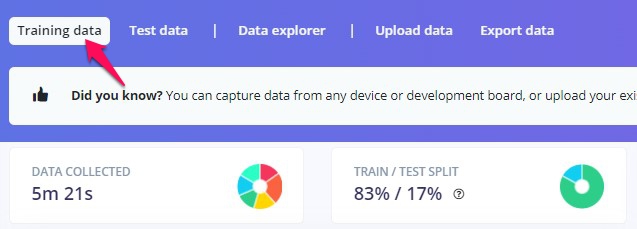
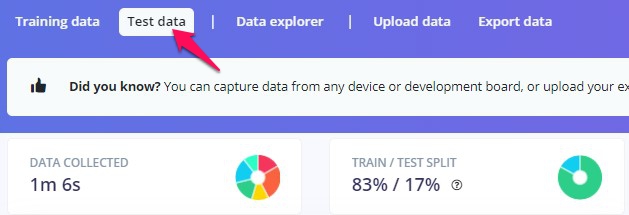
できました。このプロジェクトの場合、training dataの合計が5m 21s、testの方の合計が1m 6sになりました。
ながいみちのり。。。
いよいよTraining
impulseの構築
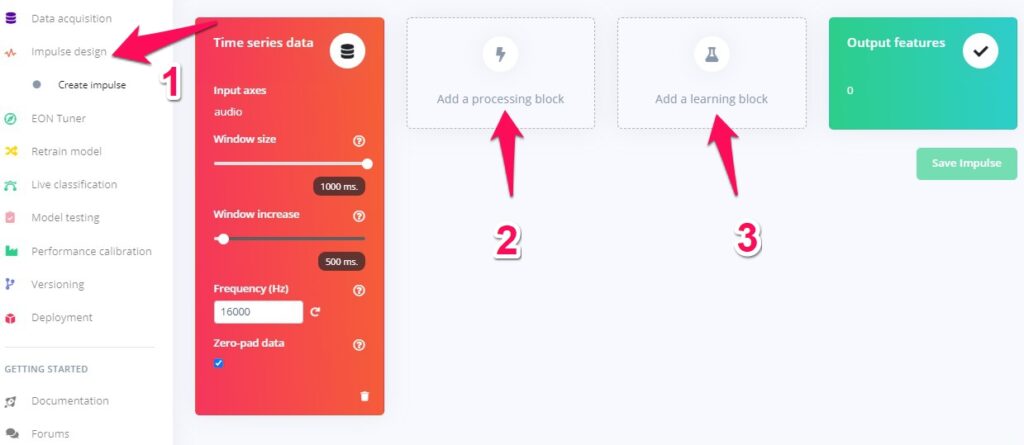
まず、データの前処理を含むパイプラインを構築します。edge impulseではimpulseと呼んでいます。左のメニューバーの、impuluse designをクリックすると次に示すような画面が出ます。
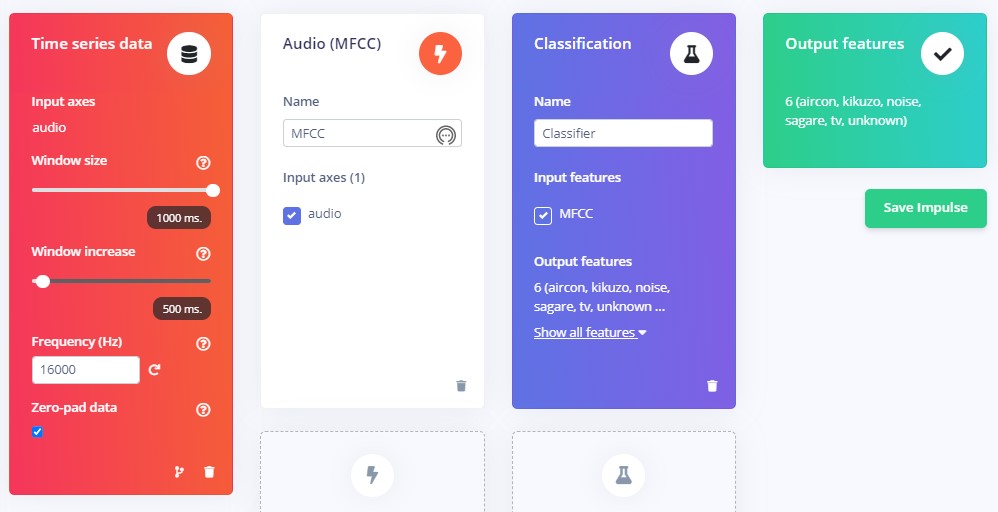
最初のブロック、Time series dataはすでに入力されているはずです。Window sizeが1000ms、Window increaseが500ms、Frequencyが16000になっているのを確認します。Window sizeは上で説明したように、時間で流れる連続データを、どの幅を持ってみるか、というものです。その次のWindow increaseは、枠をどのぐらいスライドさせて流れるデータを見るかというものです。設定は500msになっています。これは1000msの幅を持った枠を500msづつずらしてみていくということです。いま、枠の幅が1000msなので、前にみた枠の後ろ半分が重なるように次を見ていくという設定です。一つ前の枠で …おは と見えたものが、次の枠では おはよう その次には よう… と見えるという感じです。重なりを持たせながら枠をずらすことで、どこかのタイミングでうまくことばを捕まえることができるという寸法です。2のprocessing blockにはAudio(MFCC)、3のlearning blockにはclasificationを選択してください。それぞれの箇所をクリックすると選択肢が表示されますので、Addボタンで選んでください。
最終的にこうなります。Save Impulseをクリックして保存します。
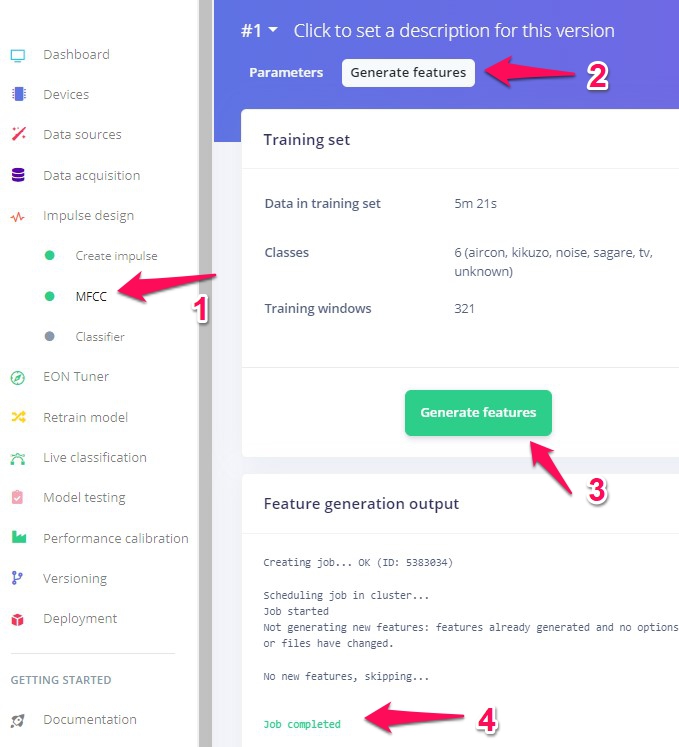
左のメニューバーのMFCC(1)、表示されるGenerate features (2)、Generate features (3)の順にクリックして、音のデータからより特徴を反映したデータへの変換を行います。Job completed (4)と表示されたら作業完了。
ここまではいったい何をしたんだ、trainingはまだなのか、されたのか、もしかして?と思うかもしれません。まだです。今回neural networkをtrainingするのですが、もとの音データは16kHzでサンプリングされていて、その1秒分が1サンプルなので、サンプル当たり16000の点データが含まれることになります。これをそのまま流し込むにはinput layerに16000のneuronを用意する必要があります。また、点データの最大、最小値もサンプルごとにばらばらでしょうし、いづれにせよ、もとの音データのままではいいclassifierができづらい。そこで、16000を減らしつつ、かつ音の特徴がよく出るような、そういう処理をしました。データ点を減らしたのに、特徴がよく出るなんて、信じがたい処理ですが、そういうことが可能なのです。研究者や、こういう仕組みを身近に提供してくれている人たちに感謝します。
とにかく、集めた音データが、neural networkに注ぎ込める形になりました。先へ進みましょう。
Training!
左メニューのClassifierをクリック。(2)の部分はTutorialに従ってAdd noise -> Lowなどとしました。(3)のtargetには使いたいdeviceをセットします。そんなのないや、という場合でも何か選んでおきましょう。
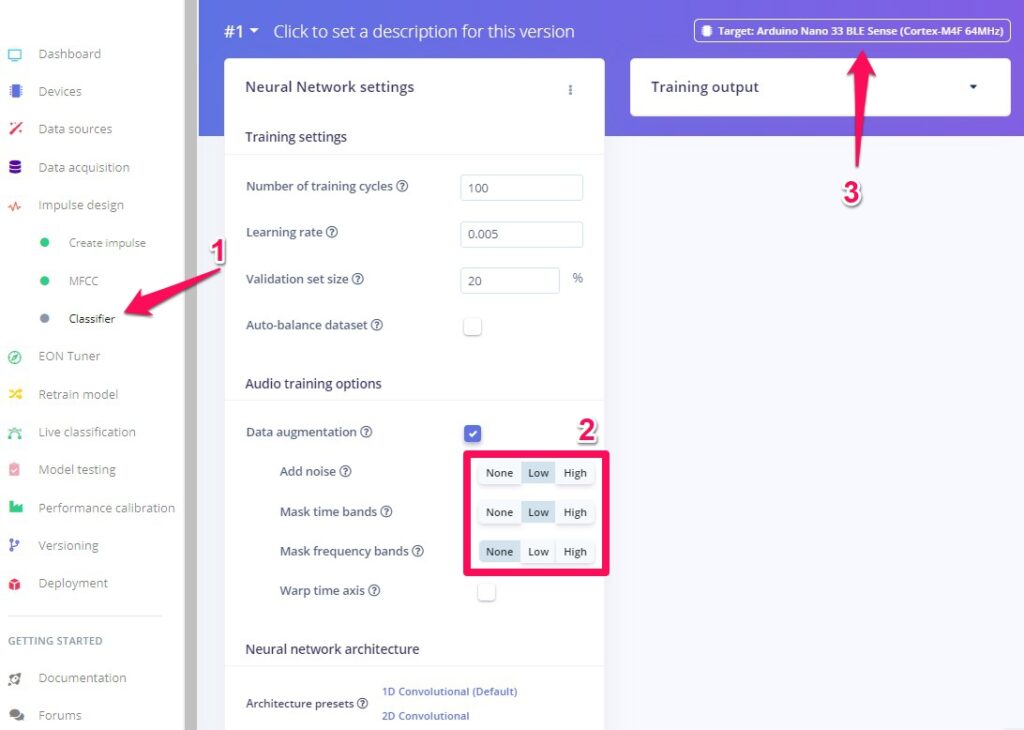
画面をスクロールダウンしてください。今回のNeural network architectureがあります。Input layer (650 features)となっていますね。これは入力サンプルが650の点データからなるデータであることを示しています。16000あった点が650に!すごいですね、FFT -> MFCC。確かに、MFCCのところでみることのできる、この図、よーく見てください。たて13マス、横50マスからなっています。13×50=650。そう、これがFFT -> MFCCで変換された音データの見た目です。データ点の数が650。これがnetworkにfeedされます。networkの出口、Output layerが6classesなのは、今回、kikuzo, sgare, tv, aircon, noise, unknownの6つのラベルへの分類だからです。それ以外の部分はedge impulseにおまかせ、です。間のlayerたちについてもわかるようになりたいですね。Dropoutは、いくつかのneuronをあえてつぶすという処理で、その方が結果が良くなるらしいのです。面白いですね。
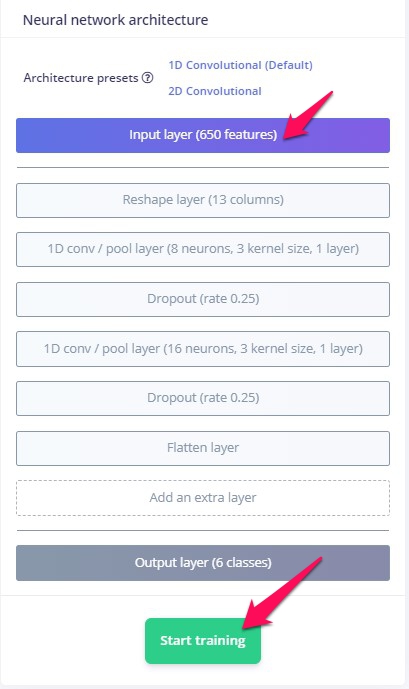
はい、すみません、ながながと。一番下のStart trainigボタンをおして、trainingを行います。右側にログがつらつらと流れ、Job completedと出たら完了です。
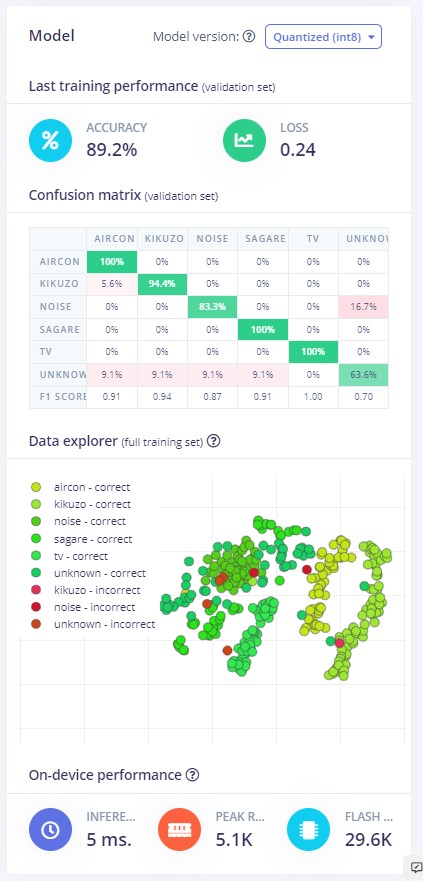
今回はこんな結果になりました。すごくいい結果です。Confusion matrixを見ます。aircon、sagare、tvについては100%! noiseの16.7%がunknownとして判定されていますが、これはどうぞ、お好きに、という部分ですよね。なぜならunknownやnoise判定はcounterなので、これから作るkikuzoリモコンには何の影響もないのです。noiseがnoizeとunknownで閉じていることがいい結果なのです。unknownがいろいろに散っていますが、これはそれなりにそう聞こえるのかもしれません。Data explorerの点にマウスカーソルを持っていくとサンプル名が見えるので、いったいどういう音がどう間違って判定されたのか追跡することができます。便利すぎですね、こりゃ。
舞台裏を見たいあなたは
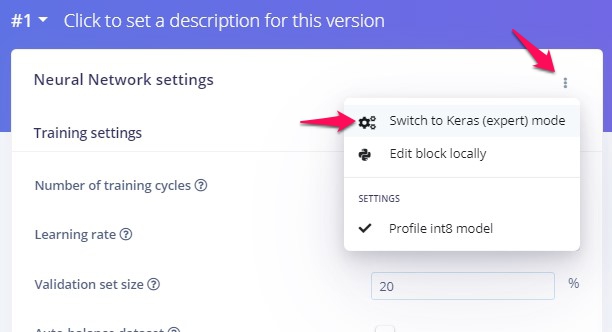
ellipsisをクリックしてSwitch to Keras (expert) modeを選ぶと、tensorflow-kerasを用いたpython codeを見ることができます。
ここではコードを見るだけでなく、parameterを編集してtrainingを調節することができます。これまたすごいですね、ありがとう、edge impulse。
判定させてみる
ケータイかパソコンを使う場合
対応deviceなしに手っ取り早く試してみることができます。
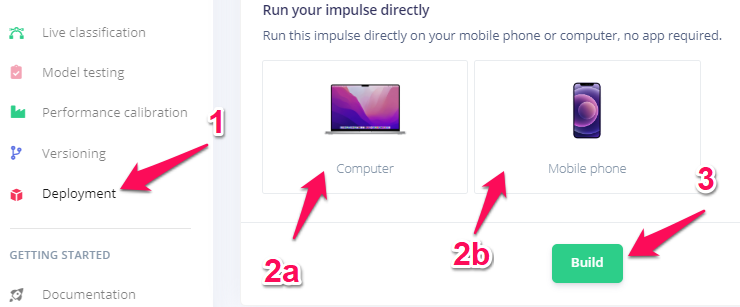
左のメニューからDeploymentをクリックして、Run your impulse directlyまでスクロール。パソコンで試す場合は2a、ケータイで試す場合は2bを選択してBuildをクリック。
ケータイの場合はURLがQR codeで表示されますのでスキャンしてアクセス。どちらの場合もマイクへのアクセス許可を聞かれますので、許可してください。
あとは話してみるだけ。
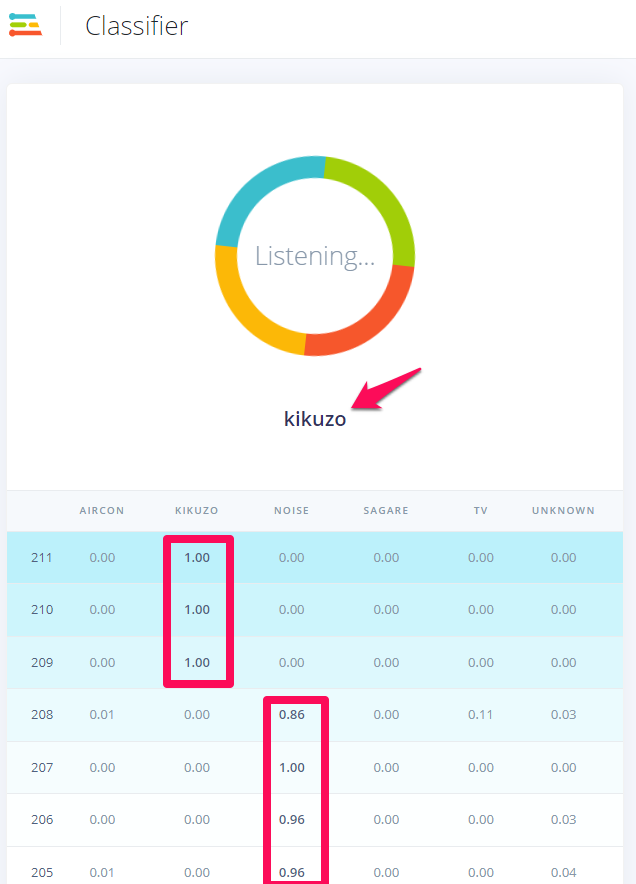
下の図は、きくぞう、といった時の判定の様子です。それまでnoise判定がつづいていたところからkikuzo判定に移り変わっています。表示されている数字は確率で、1が最高値です。
ちょっと困ったのが、どうやって止めるんだこれ?です。とりあえず、ブラウザのタブやウインドウそのものを閉じましたが、何かいい方法があるかもしれません。。。
対応deviceで遊ぶ場合
こちらは説明ページを読んで自力で進むガッツがある人向けです。コマンドラインツールのインストールと、お持ちのdevice用のfirmwareを導入する必要があります。
Officially supported MCU targetsの一覧がこのページにあります。使いたいdeviceの名前がリンクになっているので、そこをクリックして説明ページを開き、自力で読み進めてください。pythonやNode.jsのインストールも含まれて来るので、ここで手短に説明できる自信がありません。すんません。
結局、必要なのは、
- edge-impulse-daemon
- edge-impulse-run-impulse –continuous
です。最初のコマンドはコマンドラインをedge impulseのアカウントとプロジェクトに接続するためのもの、二つ目が判定プログラムを走らせるためのものです。
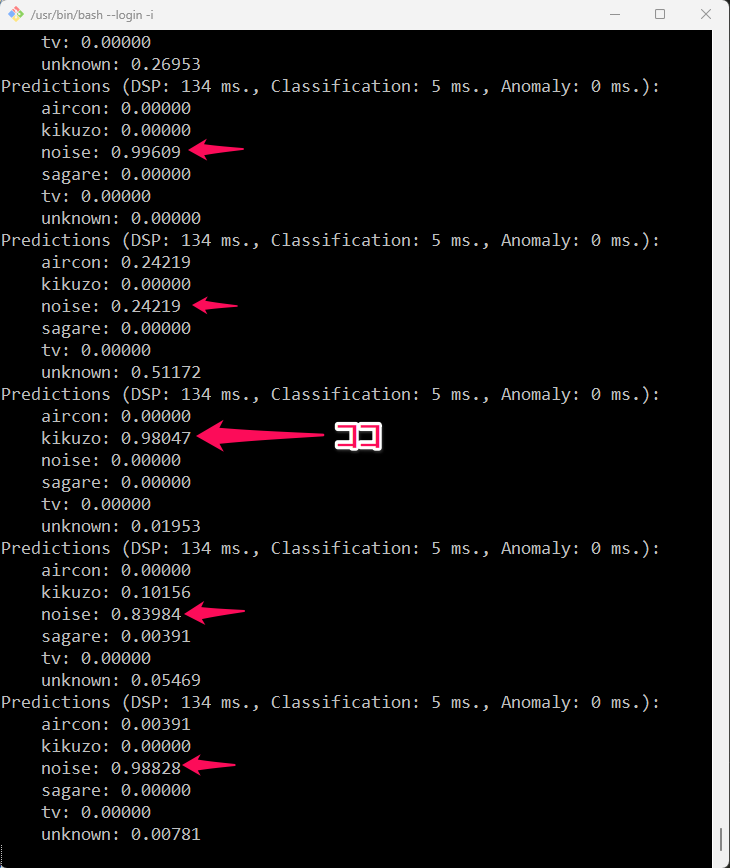
下の図は、今回の判定プログラムをコマンドラインから走らせて、きくぞう、といった時の様子です。kikuzoの値が一度高くなって、うまくcaptureできていることがわかります。
Deploymentのページからは対応deviceごと、あるいはArduino libraryとしてなど、さまざまな形でtrainingによって得られたモデルとそれを使ったコードを得ることができます。サンプル集めからtrainingまでは結構大変で少々わかりにくいところもあったので今回記事にしてみました。みなさんもいろいろ試してみてください。小さなdeviceがうまく判定結果を出す様子を見るのは楽しいですよ。これがedge computingかー、って思えます。
こんなときどうする集
Edge impulseのweb interfaceはよくできているのですが、慣れるまでは戸惑うことも多いです。Tutorialを見ながら最初から最後までやってみる時には問題が少ないのですが、別の日に続きをしようとしたりすると途端にあれ?これってどうやるんだ、ということが起こります。実際に自分が困ったことをもとにいくつか書いておきます。
一番いいのはまず一通り自分でやってみて、そのあと1-2回、試してみることだと思います。ぜひ試してください。
ケータイをつなぐQRコードはどこ?
もう少しサンプルを足したいな、と思ったのだが、あれ?どうやるんだっけ?QRコードはどこから?
いくつか到達方法があると思いますが、これでいけます。
左メニューのDashboard -> Aquire dataのちょい下、LET’S COLLECT SOME DATAで、Use your mobile phoneが見つかります。Show QR codeをクリック。
training-testの切り分けがされてしまっている。全部trainingに振って出直したい。
サンプル追加の時にうっかり自動で振り分ける、にしてしまったり、すでにtrainingが済んだところへもう少しサンプルを足したりしてやり直したい、と思うことはあるはず。以下のようにします。
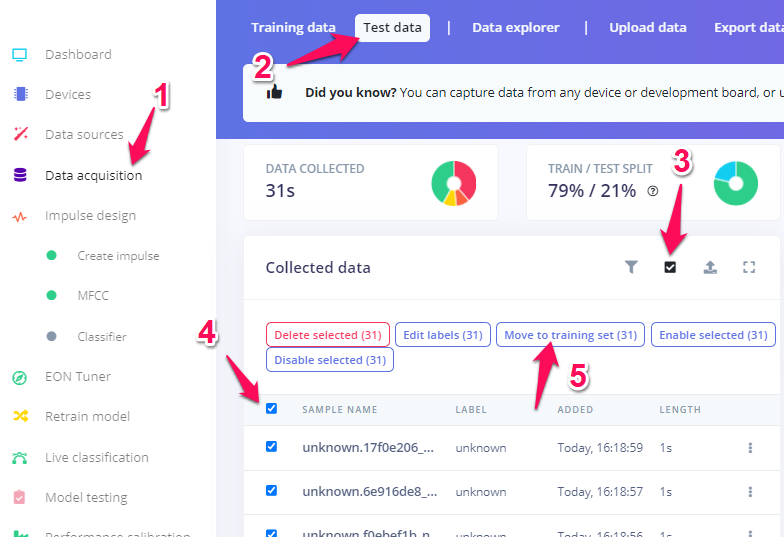
(1)左のメニュー、Data qcuisition
(2)Test dataをクリック
(3)この小さいチェックボックスをクリック
(4)一番上のチェックボックスをクリックしてすべて選択
(5)Move to training setをクリック
移動するけどいいですか、というダイアローグがでるので、賛成方向のボタンを押してください。これで右のドーナツが一色になり、小さい赤三角がでるはずです。
このあとの予定
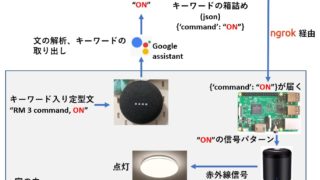
きくぞうさんを呼び出して、エアコンとテレビのスイッチをon-offする仕組みを作ります。ずいぶん前に買って一つだけ余っているRM-3を使います。
Mar30, 2024追記
結局、RM-3ではなく、赤外線送信部分はIR LEDで作ることにしました。下の記事をご覧ください。