モーションセンサーでひらがな認識
はじめに
これまで下の3つの記事を通じて画像と音声を対象とした機械学習に触れました。
- Microsoft lobeで機械学習:得られたtfliteモデルを使ってRaspberry pi上でLegoブロックの分類をする
- Teachable Machineで機械学習:Coral EdgeTPU+Raspberry piでハンドサインを認識させる
- edge impulseで機械学習:リモコン忍者kikuzoに音認識(単語)させるための準備
今回はモーションセンサーからのデータを用いたひらがな文字認識に挑戦します。
何をしたいか

もし鉛筆にしがみつくことができたとしたら、鉛筆の動きだけから書かれた文字を言い当てることができるか?という、乗り物酔いしそうな想像をしてしまいました。
そこで、自分の代わりにaccelerometer+gyroscopeの6軸モーションセンサーにしがみついてもらい、ぐりぐりとひらがなを書いて何度もデータをとり、得られたデータで判別のためのモデルを構築してみます。構築にはtensorflowを用います。得られたモデルを使って、実際にどんな感じで文字(ひらがな)が判別されるかを見てみることにします。
入力デバイスの工作
一文字分のデータをとるために
文字のデータは一文字づつとりたい。どうやって開始と終了を決める?が最初の課題でした。センサーはプログラムの開始と同時にデータを送り始めますので、いつ記録を開始して、いつ終了するのか、をコントロールしなければなりません。試行錯誤の後、ペンがタッチセンサーにつないだパッドに触れている間だけ記録する、という方法に落ち着きました。文字によってはいったんペンがパッドから離れるものがあるので、どの文字も一筆書きで書くことにしました。
材料
用いたセンサーとマイクロコントローラーは以下の通りです。プログラムはArduinoIDEで書きました。
- Adafruit QT Py – SAMD21 Dev Board with STEMMA QT(A0-A3がcapacitive touch inputとして使えます。センサーボードより小さい!)
- Adafruit LSM6DSOX 6 DoF Accelerometer and Gyroscope – STEMMA QT / Qwiic(STMicroelectronicsのセンサー!)
他にはSTEMMA QTケーブルなど以下の通りです。
- STEMMA QT / Qwiic JST SH 4-Pin Cable – 200mm Long
- Conductive Nylon Fabric Tape – 8mm Wide x 10 meters long
- タッチペン(先が金属メッシュのものを用いました)
- タッチをよく検出し、表面がつるつるでタッチペンがよく滑る金属板
- 台を作るためのLEGOパーツと両面テープ
- USB-Cケーブル(QT PyとPCとを接続)
下に工作した入力デバイスを示します。
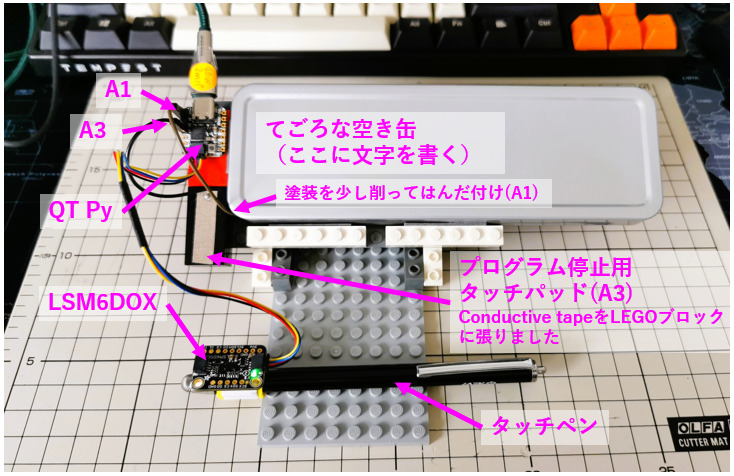

上の写真にあるものに落ち着く前に、手作りタッチペンとconductive tapeで作ったタッチパッドを用いていました(Fig. 2.3)。何度もデータを取ったりしてテープの間に微妙な隙間ができてしまったためか、摩耗のためか、そもそもペンの先端が鉄球で接触が面というより点になるせいか、入力途中でタッチが途切れることが頻発し始めました。若干の途切れはプログラム側で許容するようにしたのですが、イタチごっこ的状況になったので、先端が柔らかめのタッチペン(以前はどこにでも売られていたのに、見つけるのに少し苦労しました)を買って上のように作り直しました。少し押し込み気味に書く必要がありますが、慣れればうまくいきます。

入力デバイス用Arduino code
センサーからのデータをカンマ区切りでシリアルに出力するだけのプログラムです。データは、accelerometerのx, y, z, gyroscopeのx, y, zにつづいてA1(ペンタッチ)とA3(終了シグナル)のcapacitive touchの入力値という順です。
サンプリングレート(ある時間内に何回読み取るか)なんですが、簡単な字でも1秒かけて書くとして、30点/1秒ぐらいとればおおよそ特徴は拾えるのではないか、と漠然と考え、loopのdelayMicroseconds()を30000としました。30ミリ秒待ち、なので、1秒間でおよそ30+回ぐらい読み取りがされるはずという算段です。書くのに2秒かかる文字からは60点ほどのデータが得られることになります。サンプリングレートを上げると(delayMicroseconds()のargを小さくする)、解像度高くセンサーの動きを拾うことになりますので、微妙な動きを反映させることができるかもしれませんが、今回の目的、ひらがなを書く時の筆の動き、には1秒に30点ぐらいでいいのではないかと考えました。
Code file(acc-gyro-Reader-v1.ino)はGitHubに上げておきました。
データ収集
データ記録用python code
入力デバイスからUSBに送られてくるセンサーデータを一文字分づつ(A1がタッチを検出している間)ファイルに保存していくプログラムです。ラベルとなる文字をargとして与えて使います(file名のprefixになります)。Code (serialRecorder-touch-robust2.py)をGitHubに上げておきました。
# 例えば「き」のデータを保存する場合、
python serialRecorder-touch-robust2.py ki
A3ピンにつないだconductive tapeに触れるとプログラムが終了します。
で、ki-001.csv, ki-002.csv,,,というように連番のファイル名でデータが保存されていきます。
「あ」から「ん」まで、それぞれ20個づつデータを取得して一つのフォルダに保存しました。46文字、合計920ファイル。結構大変でした(さらりと書きましたが、試行錯誤段階ではこれを何度か繰り返しました)🥴。
tail-chopper code
これ、細かい話になるんですが、ペンを動かす向きや速さによって、文字を書いている途中でタッチが一瞬とぎれることがあり、一瞬なら無視するための仕組みを上のcodeに入れてあります。しかし、そのせいで文字の書き終わりに若干余計なデータが記録されてしまいます。それをどけるためのコードが、tail-chopper.pyです。これもGitHubに上げておきました。もし上のコードでデータとりをする際には、得られたファイルをこのcodeで処理して余計なしっぽを除いてください。使い方は簡単で、上で得られたcsvファイルの入ったdirectoryへのpathをargとして与えるだけです。そのdirectory内の.csvファイルがすべて処理され、元のファイルに”-no-tail”というpostfixのついたファイルがcurrent directoryに保存されます。
ここまでで素材データの準備は完了です。次は前処理です。
データの前処理について
今回構築するトレーニングネットワークは、固定長の入力を期待します。文字入力のデータは長さが(時間方向に)様々ですので、前処理としてinterporationを使ってすべて同一の固定数(30点)スリットから見えるデータに書き換えます。なぜ30なのか、はwith no reasonです。なんとなく、です。いくつかの文字について、interporate前後のデータをグラフに書いてみて、30取れば形がさほど変わらないことがわかったので、30で進むことにしました。
得られた生データに対し、二つの処理をしてトレーニングネットワークに注ぎ込めるようにします。
- 固定長データにする:interporateで時間方向30点での値を計算。accelerometer, gyroscopeからの x, y, zそれぞれ30点。合計は(2 sensors) x (3 axis) x (30 points) = 180/文字となります。
- 値の振れ幅を0から1に閉じ込める:それぞれの軸の最大値を1最小値を0としてすべての値を0と1の間に閉じ込めます。これをしなくてもトレーニングネットワークには注ぎ込めますが、今回の目的は文字の認識にあり、元気に書けているか、優しく書けているか、といった要素は関係ありませんので、最大は1最少は0とする変換をはさみます。
トレーニング
試行錯誤の末に得られた、ほかの人が見てもわかりづらいnoteをちょっぴりきれいにしたjupyter noteを用意しました。そちらをご覧ください(GitHub)。(conv2d-train.ipynb)
最終的にモデルファイル(.h5)とindexと文字ラベルとをつなぐためのpython dictを漬物にしたもの(.pkl)が得られます。この二つをmodel-tester-CNN-3.pyに渡すことになります。このコードもGitHubに上げておきました。
モデルを使ってみる
model-tester-CNN-3.pyにトレーニングで得られたmodelファイルと辞書漬物ファイルとを渡します。QT PyのA3につないだパッドにタッチするとプログラムを終了することができます。
動作の様子
データ収集のdemoと、modelを使ってみている様子を動画にまとめました。
「し」、「そ」、「の」がどうもうまくいきませんでしたが、そのほかはわりと良好な認識度でした。
補足など(毎回長いので後ろに置きました)
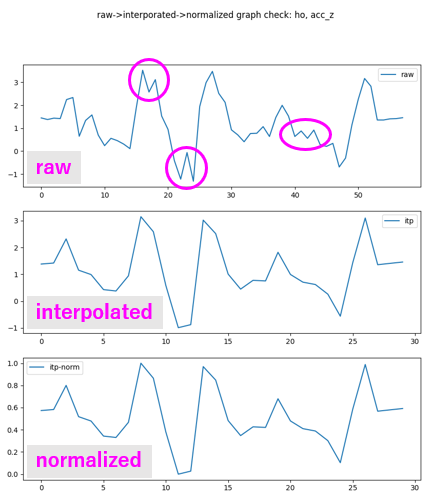
interporation前後でのグラフプロット
Interporationを使って時間軸方向(横軸)に30点だけデータを拾っていった場合、どうなるかをグラフで示します。例として、ひらがな「ほ」の、加速度のz軸方向のデータを取り上げます。
Rawデータは横軸方向に60点近くとれています(raw)。これを横軸30点だけ拾っていったものが真ん中(interporated)、最後が縦軸のスケールを0から1に変換したものです。30点に観測点を減らすような処理をしても、特徴がうまく拾えているのがわかります。最後はただ軸のスケールを取り直しただけなので、真ん中と形はかわりません。
また、丸で囲んだ小さなギザギザは、interporateで失われることもわかります。これが良いことなのか、悪いことなのかは、考察の対象です。余計な、あるいは別の文字にもあって混乱の原因である動きが無視されるのでよい、のか、肝心な特徴が拾えてなくて判定精度が落ちる、のか。考えてもわからないので、こういうことがあったとだけ覚えておいて、先に進むことにします。
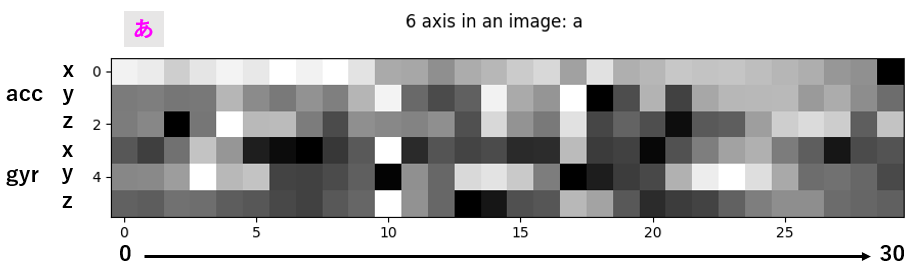
6軸まとめて画像として見てみる
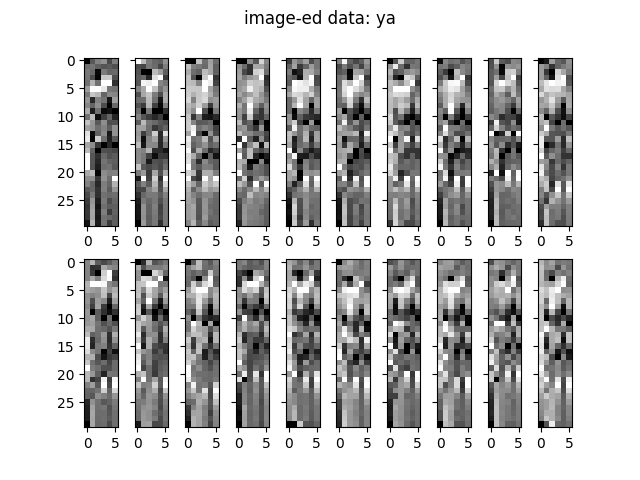
6軸分のデータを画像としてまとめてみます。画像といっても、1軸の1点あたりのデータを一つのタイルの色として並べたものです。matplotlibのimshow()が作ってくれます。Normalizedした「あ」のデータのひとつを例として下に示します。1が白,0が黒のスケールです(cmap=’gray’)。グラフの山、高いところが白、谷になった低いところが黒です。山の高いところには雪、と思ってにらんでいると、デコボコして見えてきます。
一筆書きしたときにどうしても似てしまいやすい文字の6軸データを並べてみます。(ここにはそれぞれ一回分の読み取り分のデータしか示しませんが、同じ文字のデータどうしは再現性良く似ていることも重要です)

どうでしょう。似てるような、違うような。これらがうまく分別できればいいですねってわけです。どうしても分離がうまくいかない字がある場合、入力に特徴を付けるという手があります。たとえば「い」は極端に横長に、「り」は幅をせまく縦に長く、とか、「い」はゆっくり、「り」はものすごく早く書く、など。独自の記法(筆法)で分離度を上げるという手です。こういうことを考えるのも楽しみのひとつです。
そもそも文字には、はね、とめ、はらい、まるみ、そり、かど、を付けて書くときれいにみえますよ、というルールがあるので、そういうものを参考にすると分離度が上がるように思います。テキトーにめりはりなく書く形の悪い字は、機械にとっても分離が悪い、すなわちみにくい、読みにくい、ということなのかもしれません。おもしろいです。
畳み込み、そもそも畳むってなんだ
Convolutionalの訳にあたる部分なんですが、調べてみると、convoluteはぐるっと囲んでひとまとめにして巻き取る、というような雰囲気の語で、convolutedとすると(結果として)複雑でわかりにくくなっている状態をあらわすようです。巻き取ったり畳んだりしてしまえば当然中身は見えなくなってしまうので、そういう意味が出るのだと思われます。
どう畳むか、のところで書きますが、畳み込みの処理はデータを風呂敷のように広げた状態で、角からもう一方の角に向かってつづら折り的に進みます。左から右、左に戻って少し降りて左から右、という具合に。この処理の進み方自体を畳み込みといっているように思います。また、一か所一か所で行う処理、ある区画(kernelといいます)に施す数値処理(filter)自体も、いくつかのデータ点からなる区画を一つのデータ点に代表させる処理なので、これもデータを畳み込んでいるように見えます。さらにpoolingという、ある大きさの区画の最大値を代表値として束ねていく処理などは、これまた畳み込みともいえそうです。
全部ひっくるめてconvolutionalだと、勝手に理解しておくことにします。
畳み込み、なぜ畳むのか
ですね。専門の方には違う!と叱られるかもしれませんが、今のところ、二つ意味があるように思います。一つはfilterでの処理により、データの持つ特徴を際立たせること。これはある区画に入る複数のデータ点を見ることで引き出されます。画像の場合なら区画という言い方がぴったりしますが、今回のセンサーデータの場合ではx, y, zを縦に切って区画とすることも可能です。ペンの動きは当然x, y, zに対して何らかの協奏的特徴があるかもしれません。今回は試しませんでしたが、accelerometerとgyroscope両方のデータをまとめた区画をとるのもオモシロイかもしれません。
畳み込みのもう一つの意味は、データを小さくすることです。データの特徴を際立たせつつ、データ点の数を小さくすることができれば、スピードの上でも、また、それほど計算パワーのない機器でもモデルを動かすことができるという可能性を生みます。
今回、畳み込みがいいだろう、と漠然と考えた理由の一つは、6軸データを眺めた時に緩やかーにデータが右へ左へぶれていたことです。できるだけ同じように文字を書こうとはしたのですが、(とくにちゃらんぽらんな私の場合)どうしても筆の運びがぶれるため、こんなふうでうまくいくのだろうか、と考えていたその時、パンダの画像判定ではパンダは写真のいろいろなところに写っていたよなあ、少々右、上、真ん中。画像判定の例ではよくCNNが使われており、畳み込めば少々のぶれを吸収しつつ特徴は出るのではないか、と思ったというのは、とってつけた理由です。実際は、普通の畳み込みなしのNNで、ああだこうだ試行錯誤を繰り返した後、metric learningというものすごく面白そうなものを見つけてしまい、道草してあちこちかじっている間に嫌気がさして、早く前に進め、と自分に言い聞かせてCNNでねばっていたら、思っていたよりいい結果が出た、というのが本当のところです。
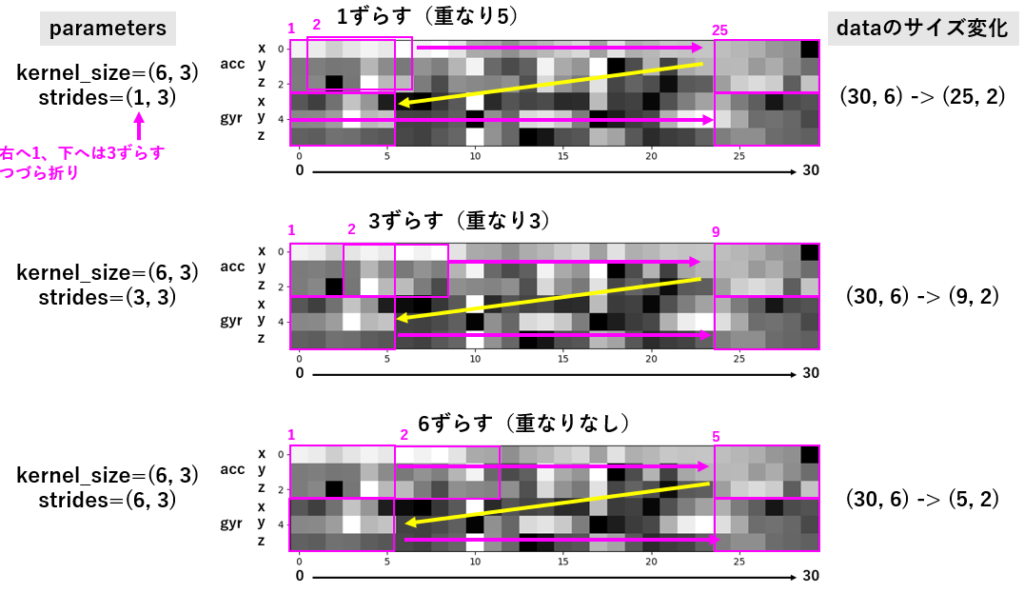
畳み込み、どう畳むか:つづら折りルートの設定
いったいどう畳めばいい分離ができるか、いくつか畳み方を試してみました。まず、6軸まとめてプロットでいうところの、(ヨコ6, タテ1)の大きさの区画(kernel_sizeで設定)を、右へ1づつ、3づつ、6づつずらす場合を示します。
区画はヨコ6なので、1づつ3づつずらしの場合、重なりを保ちつつ次の区画をみていくことになります。ヨコの大きさと同じ6ずらす場合には重なりなしに次を見ていくという方針です。下へ大きさとずれは1に固定し、x, y, zそれぞれは混ぜて考えない、という心づもりです。

同様に、(ヨコ6, タテ3)の区画で、accelerometerからのxyzをひとまとめに、gyroscopeからのxyzを別のひとまとめとした区画で畳んでいく様子を下に示します。
どの畳み方がいいのでしょうか。もちろん、いい分離を提供するモデルができてくる畳みかたが「いい」ということになります。
なんとなく想像できるのは、重なりなし、だと、連続した文脈がとぎれてしまう(一筆書きという文脈が分断されるのはよくないはず)、きっと重なりはあった方がいいだろう、ということです。
accelerometer, gyroscopeそれぞれx, y, zを混ぜないで畳む方法、あるいはaccelerometer, gyroscopeそれぞれをひとくくりとして、x-y-zを協奏したものとしてとらえる方がいいのか。さてさて、どうなるでしょうか。
それぞれ同一のtrain-test splitデータで、トレーニングを行った結果が以下の通りです。(なお、filter数は1でこのテストを行いました)
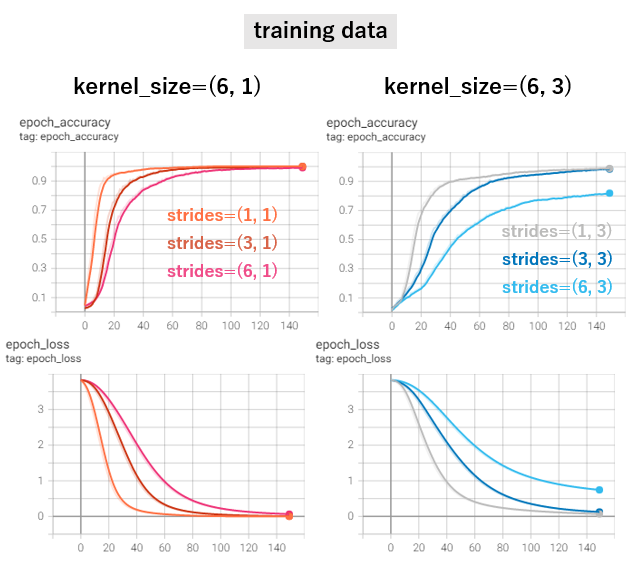
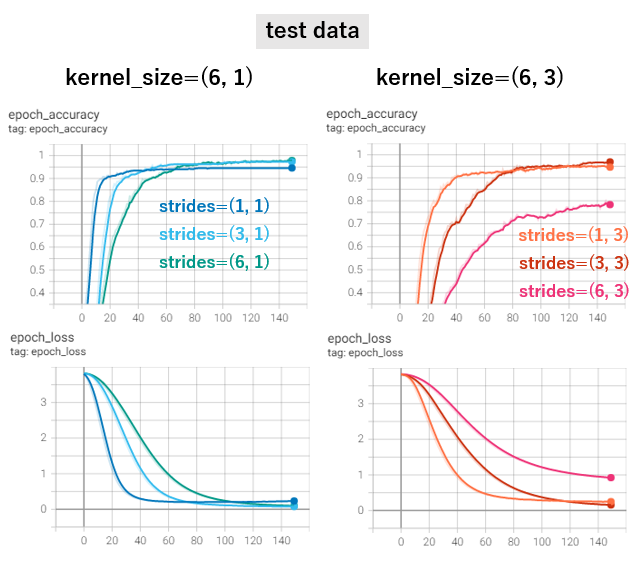
実際にできてきたモデルとペンからの入力でテストすることなしに、どれが「いい」ということはできませんが、kernel_size=(6, 3)でstrides=(6, 3)以外はどれも最終的にいい成績をだしています。特にkernel_size=(6, 1)でstrideを小さく(1, 1)とると今回比べた中では最速でloss値が0に近づいていきます。
ペンにつけたモーションセンサーのデータで、ひらがな46個が分別できそうだなんて、すごいですね、こりゃ。
本来こういう比較は、なんどもtrain-testのsplitを行ってトレーニングを繰り返したうえでパラメター設定の良し悪しを云々すべきだと思いますが、趣味の実験ということで、ご勘弁を。
畳み込み、それで、実際どう畳まれたのか見たい
Tensorflowでは、model中のlayerを引っ張り出して、そのlayerでdataがどうなっているのかを調べることができます。(ほかのframeworkでもできるかもしれません)
今回最終的にkernel_size=(6, 1), strides=(1,1), さらにfilters=4としてモデルを構築しました。Filterは自分で与えることもできますが、与えなければtrainingでのparameterとして最適化されます。今回のモデルで得られたfilterと、似た文字代表、「せ」と「や」のデータがフィルターでどう畳まれたのかを可視化してみました。(filter-viewer.pyをGitHubに置いておきました)

左のf1からf4が今回得られたフィルターです。なんだそれは、と思ってしまいますが、kernel_sizeを(6, 1)としたので、実体は6個の数です。その数を黒から白までの色として表現してあります。これを用いてstrides=(1,1)でつづら折りしていった結果が下につづくそれぞれの画像です。これまたつづら折りするってなんだ、と思ってしまいますが、実際行われるのはフィルタの6数と、フィルタを充てた6マスにあたる数とで演算を行って、一つの値を得ることです。フィルタをstridesで指定した分づつずらしながらこの演算を繰り返し、得られた値を順に並べていきます。これが「畳む」の実像です。
一番上は入力のもので、横に30マスありますが、畳まれたあとのものは25マスになっています。(30マス中で6マスのものを左から右に充てていくと、25マス分動かせることになります)
どうでしょう。オリジナルはところどころ似ているような、いないような感じですが、畳まれたものをみると、比較的こことここが違う、こことここが似ている、という部分がうまくあぶりだされているように見えませんか?複数のfilterを通してみることで、より多くの特徴が得られるようになります。ある意味filter数=視点数と言えます。
畳み込みまとめ
畳み込みは、
- 特徴をあぶりだすために行います。
- 一つのフィルターは一つの畳み方に相当します。
- 複数のフィルターを使うことは多角的にみることに相当します。
- どの大きさで畳むかはkernel_sizeで与えます。
- 次の畳みへの歩幅はstridesで与えます。
- フィルターの数はfiltersで与えます。
こんな使い道もあるのでは
パスワードならぬ、パス一筆書きを登録すれば、サインのように使えるのでは?という話が家族から出ました。確かに。今回は既存の文字の認識に使いましたが、モーションセンサーからのデータは文字が既存であるかどうかなどどうでもいいわけで、ぐるぐるぴっぴ、てんてんばばば、ぎざぎざどどどすぅー、みたいなパターンをシークレット一筆書き、に使えますね。
あと、もっといえばセンサーはペンにつけなくてもいいわけで、手首につけて踊って、パス踊り、とか、パスダンスとか(同じか)、ほかの人がまねできない動きならなんでも使えますね。ただし、自分でうまく再現できることが重要ですが。パス踊り対応のATMの前で、パスが通らず、あれ?こっちだったっけな、などと駅前支店のATMコーナーで残高照会のためだけに何度も踊るのは恥ずかしいですね、列も長くなるし。コピー不能なオリジナリティあふれる踊りを見るのは楽しいので、行列が長くても退屈しないかもしれませんが。